Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
Gilt für: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Tipp
Data Factory in Microsoft Fabric ist die nächste Generation von Azure Data Factory mit einer einfacheren Architektur, integrierter KI und neuen Features. Wenn Sie mit der Datenintegration noch nicht vertraut sind, beginnen Sie mit Fabric Data Factory. Vorhandene ADF-Workloads können auf Fabric aktualisiert werden, um auf neue Funktionen in der Datenwissenschaft, Echtzeitanalysen und Berichterstellung zuzugreifen.
In diesem Lernprogramm verwenden Sie das Azure-Portal, um eine Datenfactory zu erstellen. Anschließend verwenden Sie das Tool "Daten kopieren", um eine Pipeline zu erstellen, die Daten aus einer SQL Server Datenbank in Azure BLOB-Speicher kopiert.
Hinweis
- Wenn Sie noch nicht mit Azure Data Factory arbeiten, lesen Sie Introduction to Data Factory.
In diesem Tutorial führen Sie die folgenden Schritte aus:
- Erstellen einer Data Factory.
- Erstellen einer Pipeline mithilfe des Tools zum Kopieren von Daten
- Überwachen der Pipeline- und Aktivitätsausführungen.
Voraussetzungen
Azure-Abonnement
Bevor Sie beginnen, ein kostenloses Konto erstellen wenn Sie noch nicht über ein Azure-Abonnement verfügen.
Azure-Rollen
Zum Erstellen von Datenfactoryinstanzen muss dem Benutzerkonto, mit dem Sie sich bei Azure anmelden, eine Contributor oder Owner Rolle zugewiesen werden oder ein administrator des Azure-Abonnements sein.
Um die Berechtigungen anzuzeigen, die Sie im Abonnement haben, wechseln Sie zum Azure Portal. Wählen Sie oben rechts Ihren Benutzernamen und dann Berechtigungen aus. Wenn Sie Zugriff auf mehrere Abonnements besitzen, wählen Sie das entsprechende Abonnement aus. Beispielanweisungen zum Hinzufügen eines Benutzers zu einer Rolle finden Sie unter Assign Azure Rollen mithilfe des Azure Portals.
SQL Server 2014, 2016 und 2017
In diesem Lernprogramm verwenden Sie eine SQL Server-Datenbank als source Datenspeicher. Die Pipeline in der in diesem Tutorial erstellten Data Factory kopiert Daten aus dieser SQL Server-Datenbank (Quelle) in Blob Storage (Senke). Anschließend erstellen Sie eine Tabelle mit dem Namen emp in Ihrer SQL Server-Datenbank und fügen ein paar Beispieleinträge in die Tabelle ein.
Starten Sie SQL Server Management Studio. Wenn sie noch nicht auf Ihrem Computer installiert ist, wechseln Sie zu Download SQL Server Management Studio.
Stellen Sie mithilfe Ihrer Anmeldeinformationen eine Verbindung mit Ihrer SQL Server Instanz her.
Erstellen Sie eine Beispieldatenbank. Klicken Sie in der Strukturansicht mit der rechten Maustaste auf Datenbanken, und wählen Sie anschließend Neue Datenbank.
Geben Sie im Fenster Neue Datenbank einen Namen für die Datenbank ein, und wählen Sie dann OK.
Führen Sie das folgende Abfrageskript für die Datenbank aus, um die Tabelle emp zu erstellen und einige Beispieldaten einzufügen. Klicken Sie in der Strukturansicht mit der rechten Maustaste auf die von Ihnen erstellte Datenbank, und wählen Sie anschließend Neue Abfrage.
CREATE TABLE dbo.emp ( ID int IDENTITY(1,1) NOT NULL, FirstName varchar(50), LastName varchar(50) ) GO INSERT INTO emp (FirstName, LastName) VALUES ('John', 'Doe') INSERT INTO emp (FirstName, LastName) VALUES ('Jane', 'Doe') GO
Azure Speicherkonto
In diesem Lernprogramm verwenden Sie ein allgemeines Azure Speicherkonto (insbesondere Blob Storage) als Ziel-/Sink-Datenspeicher. Falls Sie noch nicht über ein allgemeines Speicherkonto verfügen, erfahren Sie unter Erstellen Sie ein Speicherkonto., wie Sie eins erstellen. Die Pipeline in der Datenfabrik, die Sie in diesem Lernprogramm erstellen, kopiert Daten aus der SQL-Server-Datenbank (Quelle) in diesen Blob-Speicher (Sink).
Abrufen des Speicherkontonamens und des Kontoschlüssels
In diesem Tutorial verwenden Sie Name und Schlüssel Ihres Speicherkontos. Den Namen und den Schlüssel Ihres Speicherkontos ermitteln Sie anhand der folgenden Schritte:
Melden Sie sich mit Ihrem Azure Benutzernamen und Kennwort beim portal Azure an.
Wählen Sie im linken Bereich Alle Dienste aus. Filtern Sie nach dem Schlüsselwort Speicher, und wählen Sie dann Speicherkonten aus.

Filtern Sie in der Liste mit den Speicherkonten ggf. nach Ihrem Speicherkonto. Wählen Sie dann Ihr Speicherkonto aus.
Wählen Sie im Fenster Speicherkonto die Option Zugriffsschlüssel.
Kopieren Sie in den Feldern Speicherkontoname und key1 die Werte, und fügen Sie sie zur späteren Verwendung im Tutorial in einen Editor ein.
Erstellen einer Data Factory
Wählen Sie im oberen Menü die Option "Resource>Analytics>Data Factory erstellen" aus:

Geben Sie auf der Seite Neue Data Factory unter Name den Namen ADFTutorialDataFactory ein.
Der Name der Data Factory muss global eindeutig sein. Sollte für das Feld „Name“ die folgende Fehlermeldung angezeigt werden, ändern Sie den Namen der Data Factory (beispielsweise in „
ADFTutorialDataFactory“). Benennungsregeln für Data Factory-Artefakte finden Sie im Thema Azure Data Factory – Benennungsregeln. 
Wählen Sie das Azure Abonnement aus, in dem Sie die Data Factory erstellen möchten.
Führen Sie unter Ressourcengruppe einen der folgenden Schritte aus:
Wählen Sie die Option Use existing(Vorhandene verwenden) und dann in der Dropdownliste eine vorhandene Ressourcengruppe.
Wählen Sie Neu erstellen, und geben Sie den Namen einer Ressourcengruppe ein.
Weitere Informationen zu Ressourcengruppen finden Sie unter Ressourcengruppen zum Verwalten Ihrer Azure Ressourcen.
Wählen Sie unter Version die Option V2.
Wählen Sie unter Standort den Standort für die Data Factory aus. In der Dropdownliste werden nur unterstützte Standorte angezeigt. Die Datenspeicher (z. B. Azure Storage und SQL-Datenbank) und Berechnungen (z. B. Azure HDInsight), die von Data Factory verwendet werden, können sich an anderen Speicherorten/Regionen befinden.
Klicken Sie auf Erstellen.
Nach Abschluss der Erstellung wird die Seite Data Factory wie in der Abbildung angezeigt:

Wählen Sie Open auf der Open Azure Data Factory StudioKachel aus, um die Benutzeroberfläche der Datenfabrik auf einer separaten Registerkarte zu starten.
Erstellen einer Pipeline mithilfe des Tools zum Kopieren von Daten
Wählen Sie auf der Azure Data Factory Startseite Ingest aus, um das Tool "Daten kopieren" zu starten.

Navigieren Sie zu der Seite Eigenschaften des Tools zum Kopieren von Daten und wählen Sie die Option Integrierte Kopieraufgabe unter dem Aufgabentyp aus. Wählen Sie nun unter Aufgabenintervall oder Aufgabenzeitplan die Option Jetzt einmal ausführen und dannWeiter aus.
Navigieren Sie zu der Seite Quelldatenspeicher und wählen Sie + Neue Verbindung erstellen aus.
Suchen Sie unter Neue Verbindung nach SQL Server, und wählen Sie dann Continue aus.
Geben Sie im Dialogfeld Neue SQL Server Verbindung unter der Option Name die Zeichenfolge SqlServerLinkedService ein. Wählen Sie unter Connect via integration runtime (Verbindung per Integration Runtime herstellen) die Option +Neu. Sie müssen eine selbstgehostete Integration Runtime erstellen, auf Ihren Computer herunterladen und bei Data Factory registrieren. Die selbstgehostete Integration Runtime kopiert Daten zwischen Ihrer lokalen Umgebung und der Cloud.
Wählen Sie im Dialogfeld Integration Runtime-Setup die Option Selbstgehostet aus. Klicken Sie anschließend auf Weiter.

Geben Sie im Dialogfeld Integration Runtime-Setup unter der Option Name die Zeichenfolge TutorialIntegrationRuntime ein. Klicken Sie anschließend auf Erstellen.
Wählen Sie im Dialogfeld Integration Runtime-Setup die Option Klicken Sie hier, um das Express-Setup für diesen Computer zu starten aus. Dadurch wird die Integration Runtime auf Ihrem Computer installiert und bei Data Factory registriert. Alternativ können Sie die Installationsdatei über die manuelle Setupoption herunterladen, die Datei ausführen und die Integration Runtime mithilfe des Schlüssels registrieren.
Führen Sie die heruntergeladene Anwendung aus. Der Status des Express-Setups wird im Fenster angezeigt.

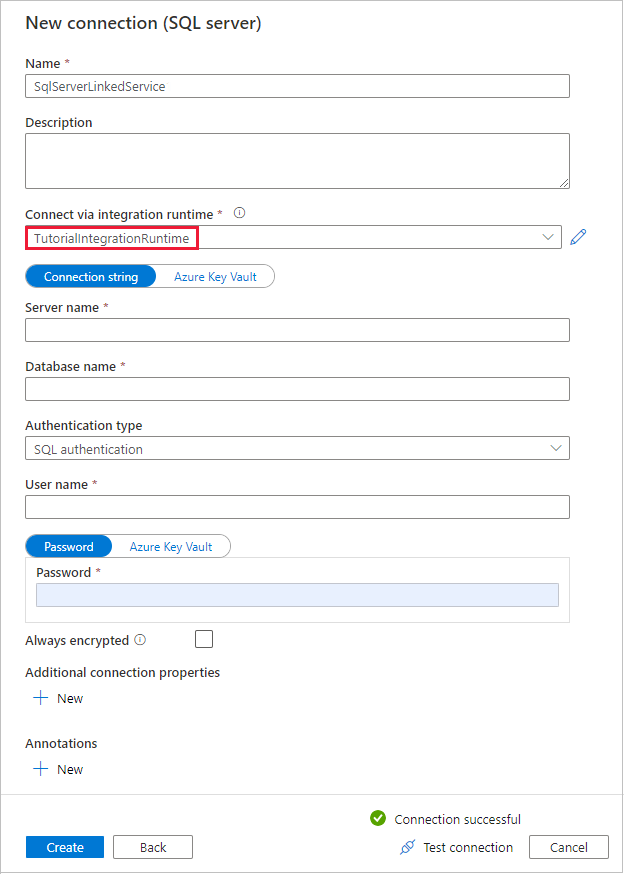
Vergewissern Sie sich im Dialogfeld Neue Verbindung (SQL Server), dass TutorialIntegrationRuntime unter Verbinden über Integrationslaufzeit ausgewählt ist. Führen Sie dann die folgenden Schritte aus:
a) Geben Sie unter Name die Zeichenfolge SqlServerLinkedService ein.
b. Geben Sie unter Servername den Namen Ihrer SQL Server Instanz ein.
c. Geben Sie unter Datenbankname den Namen Ihrer lokalen Datenbank ein.
d. Wählen Sie unter Authentifizierungstyp eine geeignete Authentifizierung aus.
e. Geben Sie unter Benutzername den Namen des Benutzers mit Zugriff auf SQL Server ein.
f. Geben Sie das Kennwort für den Benutzer ein.
g. Testen Sie die Verbindung, und wählen Sie Erstellen aus.
Stellen Sie auf der Seite Quellendatenspeicher sicher, dass die neu erstellte SQL Server Verbindung im Block "Verbindung" ausgewählt ist. Navigieren Sie dann im Abschnitt Quelltabellen zu der Option EXISTIERENDE TABELLEN und wählen Sie die Tabelle dbo.emp aus der Liste aus, und wählen Sie dann Weiter aus. Basierend auf Ihrer Datenbank können Sie eine beliebige andere Tabelle auswählen.
Auf der Seite Filter anwenden können Sie eine Datenvorschau anzeigen und das Schema der Eingabedaten einsehen, indem Sie die Schaltfläche Datenvorschau auswählen. Wählen Sie Weiteraus.
Wählen Sie auf der Seite Zieldatenspeicher die Option + Eine Neue Verbindung erstellen aus
Suchen Sie in Neue Verbindung, und wählen Sie Azure Blob Storage aus, und wählen Sie dann Continue aus.

Führen Sie im Dialogfeld Neue Verbindung (Azure Blob Storage) die folgenden Schritte aus:
a) Geben Sie unter Name den Namen AzureStorageLinkedService ein.
b. Navigieren Sie unter Verbinden über Integrationslaufzeit zu dem Eintrag TutorialIntegrationRuntime und wählen Sie unter Authentifizierungsmethode den Eintrag Kontoschlüssel aus.
c. Wählen Sie unter Azure-Abonnement Ihr Azure-Abonnement aus der Dropdownliste aus.
d. Wählen Sie in der Dropdownliste unter Speicherkontoname Ihr Speicherkonto aus.
e. Testen Sie die Verbindung, und wählen Sie Erstellen aus.
Stellen Sie im Dialogfeld Zieldatenspeicher sicher, dass die neu erstellte Azure Blob Storage Verbindung im Verbindungsblock ausgewählt ist. Geben Sie unter der OptionOrdnerpfad die Zeichenfolge adftutorial/fromonprem ein. Den Container adftutorial haben Sie im Rahmen der Vorbereitung erstellt. Ist der Ausgabeordner (in diesem Fall fromonprem) nicht vorhanden, wird er von Data Factory automatisch erstellt. Sie können auch auf die Schaltfläche Durchsuchen klicken und zum Blobspeicher und den dazugehörigen Containern/Ordnern navigieren. Wenn Sie unter Dateiname keinen Wert angeben, wird standardmäßig der Name aus der Quelle (in diesem Fall dbo.emp) verwendet.

Klicken Sie im Dialogfenster Dateiformateinstellungen auf Weiter.
Geben Sie im Dialogfeld Einstellungen unter der Option Aufgabenname die Zeichenfolge CopyFromOnPremSqlToAzureBlobPipeline ein und wählen Sie dann Weiter aus. Das Tool zum Kopieren von Daten erstellt eine Pipeline mit dem Namen, den Sie in diesem Feld angeben.
Überprüfen Sie im Dialogfenster Zusammenfassung die Werte sämtlicher Einstellungen, und klicken Sie anschließend auf Weiter.
Wählen Sie auf der Seite Bereitstellung die OptionÜberwachen aus, um die Pipeline (Aufgabe) zu überwachen.
Nach Abschluss der Pipelineausführung können Sie den Status der erstellten Pipeline anzeigen.
Wählen Sie auf der Seite „Pipeline-Ausführungen“ die Option Aktualisieren aus, um die Liste zu aktualisieren. Wählen Sie den Link unter Pipelinename aus, um Details zur Aktivitätsausführung anzuzeigen oder die Pipeline erneut auszuführen.

Wählen Sie auf der Seite „Aktivitätsausführungen“ unter der Spalte Aktivitätsname den Link Details (Brillensymbol) aus, um weitere Details zum Kopiervorgang anzuzeigen. Wählen Sie im Breadcrumb-Menü den Link Alle Pipeline-Ausführungen aus, um zur Seite „Pipeline-Ausführungen“ zurückzukehren. Klicken Sie zum Aktualisieren der Ansicht auf Aktualisieren.

Vergewissern Sie sich, dass die Ausgabedatei im Ordner fromonprem des Containers adftutorial enthalten ist.
Klicken Sie im linken Bereich auf die Registerkarte Autor, um in den Bearbeitungsmodus zu wechseln. Sie können die vom Tool erstellten verknüpften Dienste, Datasets und Pipelines mit dem Editor aktualisieren. Klicken Sie auf Code, um den JSON-Code für die im Editor geöffnete Entität anzuzeigen. Ausführliche Informationen zum Bearbeiten dieser Entitäten in der Data Factory-Benutzeroberfläche finden Sie unter die Azure Portalversion dieses Lernprogramms.

Verwandte Inhalte
Die Pipeline in diesem Beispiel kopiert Daten aus einer SQL Server Datenbank in Blob Storage. Sie haben Folgendes gelernt:
- Erstellen einer Data Factory.
- Erstellen einer Pipeline mithilfe des Tools zum Kopieren von Daten
- Überwachen der Pipeline- und Aktivitätsausführungen.
Eine Liste mit den von Data Factory unterstützten Datenspeichern finden Sie unter Unterstützte Datenspeicher und Formate.
Fahren Sie mit dem folgenden Tutorial fort, um mehr über das Kopieren von Daten per Massenvorgang aus einer Quelle in ein Ziel zu erfahren: