你当前正在访问 Microsoft Azure Global Edition 技术文档网站。 如果需要访问由世纪互联运营的 Microsoft Azure 中国技术文档网站,请访问 https://docs.azure.cn。
适用于: Azure 数据工厂 Azure Synapse Analytics
Azure 数据工厂 Azure Synapse Analytics
提示
Microsoft Fabric 中的 Data Factory 是下一代 Azure 数据工厂,具有更加简化的架构、内置人工智能和新功能。 如果不熟悉数据集成,请从Fabric数据工厂开始。 现有 ADF 工作负载可以升级到 Fabric,以跨数据科学、实时分析和报告访问新功能。
在 Azure 数据工厂 或 Synapse Analytics 工作区中,管道利用链接的计算服务处理链接存储服务中的数据。 它包含一系列活动,其中每个活动执行特定的处理操作。 本文介绍在
使用 Data Lake Analytics U-SQL 活动创建管道之前,先创建Azure Data Lake Analytics帐户。 若要了解Azure Data Lake Analytics,请参阅 Get started with Azure Data Lake Analytics。
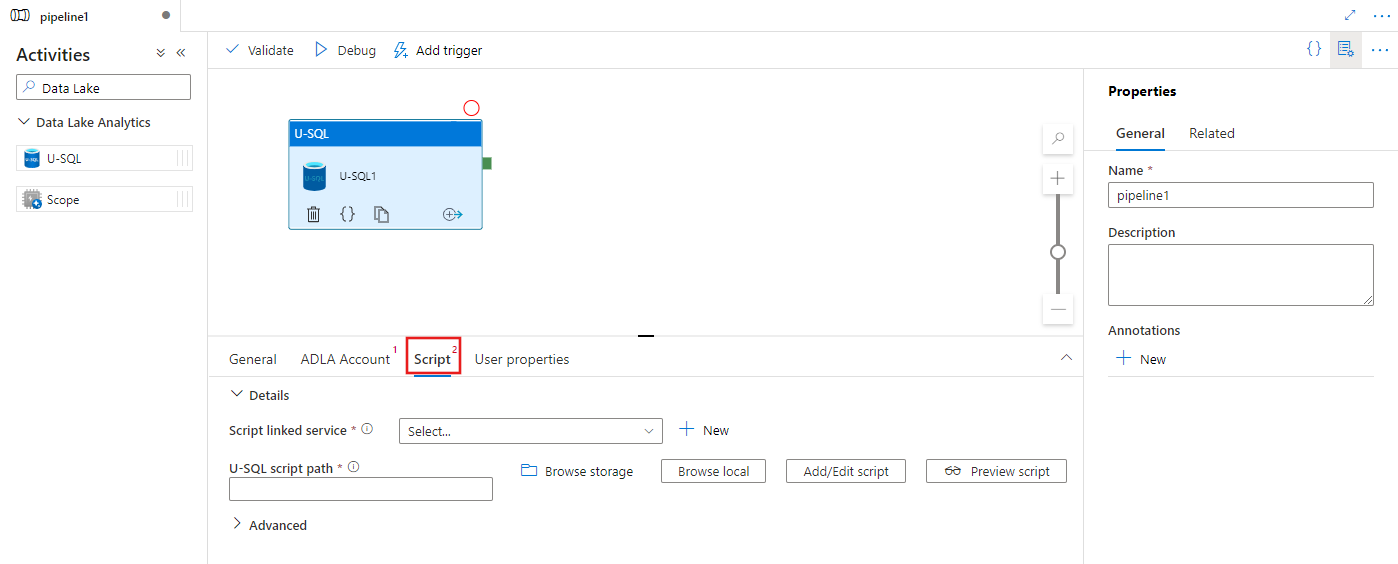
使用 UI 将 U-SQL 活动添加到用于 Azure Data Lake Analytics 的管道中
若要对管道中的Azure Data Lake Analytics使用 U-SQL 活动,请完成以下步骤:
在“管道活动”窗格中搜索 Data Lake,并将 U-SQL 活动拖动到管道画布。
在画布上选择新的 U-SQL 活动(如果尚未选择)。
选择 ADLA 帐户选项卡以选择或创建将用于执行 U-SQL 活动的新Azure Data Lake Analytics链接服务。

选择“脚本”选项卡以选择或创建新的存储链接服务,并在存储位置中选择一个路径,该路径将承载脚本。
Azure Data Lake Analytics链接服务
创建 Azure Data Lake Analytics 链接服务,将Azure Data Lake Analytics计算服务链接到 Azure 数据工厂 或 Synapse Analytics 工作区。 管道中的Data Lake Analytics U-SQL 活动是指此链接服务。
下表介绍了 JSON 定义中使用的一般属性。
| properties | 描述 | 必需 |
|---|---|---|
| 类型 | 类型属性应设置为:AzureDataLakeAnalytics。 | 是 |
| accountName | Azure Data Lake Analytics帐户名称。 | 是 |
| dataLakeAnalyticsUri | Azure Data Lake Analytics URI。 | 否 |
| subscriptionId | Azure订阅 ID | 否 |
| resourceGroupName | Azure资源组名称 | 否 |
服务主体身份验证
Azure Data Lake Analytics链接服务需要服务主体身份验证才能连接到Azure Data Lake Analytics服务。 若要使用服务主体身份验证,请注册Microsoft Entra ID中的应用程序实体,并向其授予对Data Lake Analytics及其使用的Data Lake存储的访问权限。 有关详细步骤,请参阅服务到服务身份验证。 记下下面的值,这些值用于定义链接服务:
- 应用程序 ID
- 应用程序密钥
- 租户 ID
使用 添加用户向导 为 Azure Data Lake Analytics 授予服务主体权限。
通过指定以下属性使用服务主体身份验证:
| properties | 描述 | 必需 |
|---|---|---|
| servicePrincipalId | 指定应用程序的客户端 ID。 | 是 |
| servicePrincipalKey | 指定应用程序的密钥。 | 是 |
| 租户 | 指定您的应用程序所属租户的信息(域名或租户 ID)。 可以通过将鼠标悬停在Azure门户右上角来检索它。 | 是 |
示例:服务主体身份验证
{
"name": "AzureDataLakeAnalyticsLinkedService",
"properties": {
"type": "AzureDataLakeAnalytics",
"typeProperties": {
"accountName": "<account name>",
"dataLakeAnalyticsUri": "<azure data lake analytics URI>",
"servicePrincipalId": "<service principal id>",
"servicePrincipalKey": {
"value": "<service principal key>",
"type": "SecureString"
},
"tenant": "<tenant info, e.g. microsoft.onmicrosoft.com>",
"subscriptionId": "<optional, subscription id of ADLA>",
"resourceGroupName": "<optional, resource group name of ADLA>"
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
若要了解有关链接服务的详细信息,请参阅计算链接服务。
Data Lake Analytics U-SQL 活动
以下 JSON 代码片段定义了具有Data Lake Analytics U-SQL 活动的管道。 活动定义引用前面创建的Azure Data Lake Analytics链接服务。 若要执行 Data Lake Analytics U-SQL 脚本,服务会将指定的脚本提交到Data Lake Analytics,并在脚本中定义所需的输入和输出,以便Data Lake Analytics提取和输出。
{
"name": "ADLA U-SQL Activity",
"description": "description",
"type": "DataLakeAnalyticsU-SQL",
"linkedServiceName": {
"referenceName": "<linked service name of Azure Data Lake Analytics>",
"type": "LinkedServiceReference"
},
"typeProperties": {
"scriptLinkedService": {
"referenceName": "<linked service name of Azure Data Lake Store or Azure Storage which contains the U-SQL script>",
"type": "LinkedServiceReference"
},
"scriptPath": "scripts\\kona\\SearchLogProcessing.txt",
"degreeOfParallelism": 3,
"priority": 100,
"parameters": {
"in": "/datalake/input/SearchLog.tsv",
"out": "/datalake/output/Result.tsv"
}
}
}
下表描述了此活动特有的属性的名称和描述。
| properties | 描述 | 必需 |
|---|---|---|
| 名称 | 管道中活动的名称 | 是 |
| 描述 | 描述活动用途的文本。 | 否 |
| 类型 | 对于 Data Lake Analytics U-SQL 活动,活动类型为 DataLakeAnalyticsU-SQL。 | 是 |
| linkedServiceName | 将服务链接到Azure Data Lake Analytics。 若要了解此链接服务,请参阅计算链接服务一文。 | 是 |
| 脚本路径 | 包含 U-SQL 脚本的文件夹路径。 文件的名称区分大小写。 | 是 |
| scriptLinkedService | 连接脚本所在的 Azure Data Lake Store 或 Azure 存储 的链接服务 | 是 |
| 并行度 | 同时用于运行作业的最大节点数。 | 否 |
| 优先级 | 确定应在所有排队的作业中选择哪些作业首先运行。 编号越低,优先级越高。 | 否 |
| 参数 | 要传入 U-SQL 脚本的参数。 | 否 |
| runtimeVersion | 要使用的 U-SQL 引擎的运行时版本。 | 否 |
| 编译模式 (compilationMode) | U-SQL 编译模式。 必须是这些值之一:Semantic: 只执行语义检查和必要的健全性检查;Full: 执行完整编译,包括语法检查、优化、代码生成等;SingleBox: 执行完整编译,且 TargetType 设置为 SingleBox。 如果该属性未指定值,则服务器将确定最佳编译模式。 |
否 |
请参阅 SearchLogProcessing.txt 了解有关脚本定义的信息。
示例 U-SQL 脚本
@searchlog =
EXTRACT UserId int,
Start DateTime,
Region string,
Query string,
Duration int,
Urls string,
ClickedUrls string
FROM @in
USING Extractors.Tsv(nullEscape:"#NULL#");
@rs1 =
SELECT Start, Region, Duration
FROM @searchlog
WHERE Region == "en-gb";
@rs1 =
SELECT Start, Region, Duration
FROM @rs1
WHERE Start <= DateTime.Parse("2012/02/19");
OUTPUT @rs1
TO @out
USING Outputters.Tsv(quoting:false, dateTimeFormat:null);
在上面的脚本示例中,脚本的输入和输出分别在“@in”和“@out”参数中定义。 and 该服务使用“parameters”部分动态传递 U-SQL 脚本中的“@in”和“@out”参数值。
可以在管道定义中为在 Azure Data Lake Analytics 服务上运行的作业指定其他属性,例如 degreeOfParallelism 和优先级。
动态参数
在示例管道定义中,in 和 out 参数都分配有硬编码值。
"parameters": {
"in": "/datalake/input/SearchLog.tsv",
"out": "/datalake/output/Result.tsv"
}
可改为使用动态参数。 例如:
"parameters": {
"in": "/datalake/input/@{formatDateTime(pipeline().parameters.WindowStart,'yyyy/MM/dd')}/data.tsv",
"out": "/datalake/output/@{formatDateTime(pipeline().parameters.WindowStart,'yyyy/MM/dd')}/result.tsv"
}
在这种情况下,输入文件仍从 /datalake/input 文件夹中获取,输出文件仍在 /datalake/output 文件夹中生成。 文件名是基于触发管道时传入的窗口开始时间动态生成的。
相关内容
参阅以下文章了解如何以其他方式转换数据: