適用対象: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
ヒント
Data Factory in Microsoft Fabric は、よりシンプルなアーキテクチャ、組み込みの AI、および新機能を備えた次世代のAzure Data Factoryです。 データ統合を初めて使用する場合は、Fabric Data Factory から始めます。 既存の ADF ワークロードをFabricにアップグレードして、データ サイエンス、リアルタイム分析、レポートの新機能にアクセスできます。
データ フローは、Azure Data Factory パイプラインとAzure Synapse Analytics パイプラインの両方で使用できます。 この記事は、マッピング データ フローに適用されます。 変換を初めて使用する場合は、入門記事「 マッピング データ フローを使用したデータの変換」を参照してください。
ヒント
Dataflow Gen2 の同等の変換 (マージ クエリ) については、データ フロー ユーザーのマッピングに関する Dataflow Gen2 のガイドを参照してください。
マッピング データ フローで 2 つのソースまたはストリームのデータを結合するには、結合変換を使用します。 出力ストリームには、結合条件に基づいて一致する両方のソースのすべての列が含まれます。
結合の種類
現在、マッピング データ フローでは、5 種類の結合がサポートされています。
内部結合
内部結合では、両方のテーブルで値が一致する行のみが出力されます。
左外部結合
左外部結合では、左側ストリームのすべての行と、右側ストリームで一致するレコードが返されます。 左側ストリームの行に一致するものがない場合、右側ストリームの出力列は NULL に設定されます。 出力は、内部結合によって返される行と、左側のストリームからの一致しない行です。
注意
結合条件にデカルト積の可能性があるため、データ フローで使用される Spark エンジンが時々失敗することがあります。 これが発生した場合は、カスタムクロス結合に切り替えて、結合条件を手動で入力できます。 これにより、実行エンジンがリレーションシップの両側からすべての行を計算し、行をフィルター処理する必要があるため、データ フローのパフォーマンスが低下する可能性があります。
右外部結合
右外部結合では、右側ストリームのすべての行と、左側ストリームで一致するレコードが返されます。 右側ストリームの行に一致するものがない場合、左側ストリームの出力列は NULL に設定されます。 出力は、内部結合によって返される行と、右側のストリームからの一致しない行です。
完全外部結合
完全外部結合では、両側のすべての列と行が出力され、一致しない列には NULL 値が使用されます。
カスタム クロス結合
クロス結合では、条件に基づいて 2 つのストリームのクロス積が出力されます。 同等性以外の条件を使用する場合は、クロス結合条件にカスタム式を指定します。 出力ストリームは、結合条件を満たすすべての行です。
この結合の種類は、非等結合および OR 条件に使用できます。
完全なデカルト積を明示的に生成する場合は、結合の前に 2 つの独立したストリームの派生列変換を使用して、一致する合成キーを作成します。 たとえば、SyntheticKey と呼ばれる各ストリームで派生列に新しい列を作成し、それを 1 と等しい値に設定します。 次に、a.SyntheticKey == b.SyntheticKey をカスタム結合式として使用します。
注意
カスタム クロス結合で、左右のリレーションシップの各側に少なくとも 1 つの列が含まれていることを確認してください。 各側の列ではなく、静的な値を使用してクロス結合を実行すると、データセット全体が完全にスキャンされるため、データフローのパフォーマンスが低下します。
あいまい結合
[あいまい一致を使用する] チェック ボックス オプションをオンにすると、列値の正確な一致ではなく、あいまい結合ロジックに基づいて結合を選択できます。
- テキスト パーツの結合: 単語間のスペースを削除して一致を検索するには、このオプションを使用します。 たとえば、このオプションが有効になっていると、Data Factory は DataFactory と一致していることになります。
- 類似性スコアの列: 必要に応じて、列に新しい列名を入力してその値を格納することで、行ごとに一致するスコアを格納するように指定できます。
- 類似性のしきい値: 選択した列の値間の割合の一致として、60 ~ 100 の範囲で値を選択します。

注意
あいまい一致は現在、文字列の列の型と、内部結合、左外部結合、および完全外部結合の型でのみ機能します。 ファジーマッチング結合を使用する場合、ブロードキャストの最適化をオフにする必要があります。
構成
- [右側ストリーム] ドロップダウンで、結合するデータ ストリームを選択します。
- 目的の結合の種類を選択します
- 結合条件で照合に使用するキー列を選択します。 既定では、データフローは、1 つの列について各ストリームでの同等性を検索します。 計算値で比較するには、列のドロップダウン上にマウス ポインターを移動し、 [計算列] を選択します。

非等結合
結合条件で等しくない (!=) またはより大きい (>) などの条件演算子を使用するには、2 つの列の間の演算子ドロップダウンを変更します。 非等結合では、 [最適化] タブで [固定] ブロードキャストを使用して、2 つのストリームのうち少なくとも 1 つをブロードキャストする必要があります。

結合のパフォーマンスの最適化
SSIS などのツールでのマージ結合とは異なり、結合変換は強制的なマージ結合操作ではありません。 結合キーを並べ替える必要はありません。 結合操作は、Spark の最適な結合操作 (ブロードキャスト結合またはマップ側の結合) に基づいて行われます。
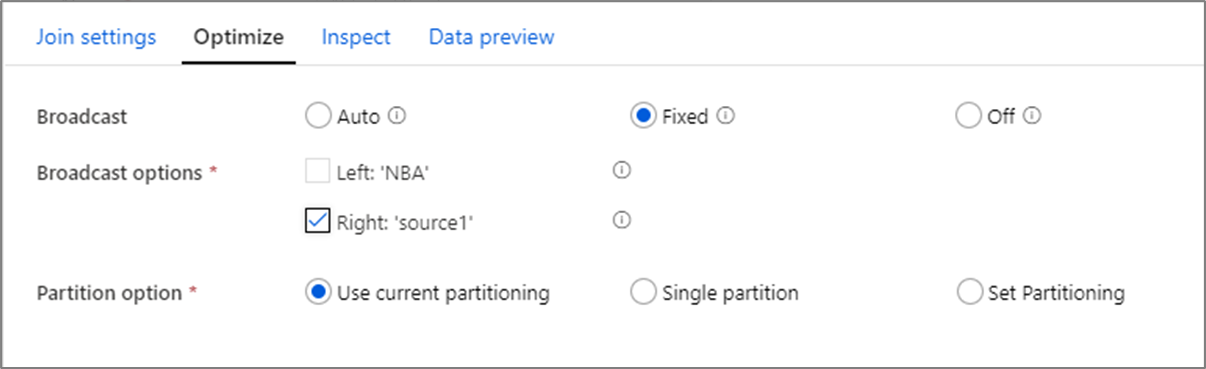
結合変換、参照変換、および存在変換では、一方または両方のデータ ストリームがワーカー ノードのメモリに収まる場合、ブロードキャストを有効にすることでパフォーマンスを最適化できます。 既定では、Spark エンジンは、一方の側をブロードキャストするかどうかを自動的に決定します。 ブロードキャストする側を手動で選択するには [Fixed](固定) を選択します。
[オフ] オプションを使用してブロードキャストを無効にすることは、結合でタイムアウト エラーが発生する場合を除いて推奨されません。
自己結合
1 つのデータ ストリームを自己結合させるには、選択変換を使用して既存のストリームをエイリアス化します。 変換の横にあるプラス記号アイコンをクリックして [新しいブランチ] を選択し、新しいブランチを作成します。 選択変換を追加して、元のストリームをエイリアス化します。 結合変換を追加し、元のストリームを左側ストリーム、選択変換を右側ストリームとして選択します。

結合条件のテスト
デバッグ モードでデータ プレビューを使用して結合変換のテストを行う場合は、小さな既知のデータ セットを使用してください。 大規模なデータセットから行をサンプリングする場合、テスト用に読み取られる行とキーを予測することはできません。 結果は非決定的です。つまり、結合条件で一致が返されない可能性があります。
データ フローのスクリプト
構文
<leftStream>, <rightStream>
join(
<conditionalExpression>,
joinType: { 'inner'> | 'outer' | 'left_outer' | 'right_outer' | 'cross' }
broadcast: { 'auto' | 'left' | 'right' | 'both' | 'off' }
) ~> <joinTransformationName>
内部結合の例
この例は、左ストリーム JoinMatchedDataと右ストリーム TripDataを受け取る TripFare という名前の結合変換です。 結合条件の式は hack_license == { hack_license} && TripData@medallion == TripFare@medallion && vendor_id == { vendor_id} && pickup_datetime == { pickup_datetime} です。この式では、各ストリームの hack_license 列、medallion 列、vendor_id 列、および pickup_datetime 列が一致する場合に true が返されます。
joinType は 'inner' です。 左側ストリームでのみブロードキャストを有効にするため、broadcast の値を 'left' に設定しています。
UI では、この変換は次のようになります。
![スクリーンショットには、[結合設定] タブが選択され、[結合の種類] が [内部] である変換が示されています。](media/data-flow/join-script1.png)
この変換のデータ フロー スクリプトは、次のスニペットにあります。
TripData, TripFare
join(
hack_license == { hack_license}
&& TripData@medallion == TripFare@medallion
&& vendor_id == { vendor_id}
&& pickup_datetime == { pickup_datetime},
joinType:'inner',
broadcast: 'left'
)~> JoinMatchedData
カスタム クロス結合の例
この例は、左ストリーム JoiningColumnsと右ストリーム LeftStreamを受け取る RightStream という名前の結合変換です。 この変換は 2 つのストリームを取り込んで、列 leftstreamcolumn が列 rightstreamcolumn よりも大きいすべての行を結合します。
joinType は cross です。 ブロードキャストが有効になっていない状態です。broadcast に 'none' の値があります。
UI では、この変換は次のようになります。
![スクリーンショットには、[結合設定] タブが選択され、[結合の種類] がカスタム (クロス) である変換が示されています。](media/data-flow/join-script2.png)
この変換のデータ フロー スクリプトは、次のスニペットにあります。
LeftStream, RightStream
join(
leftstreamcolumn > rightstreamcolumn,
joinType:'cross',
broadcast: 'none'
)~> JoiningColumns