Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
Questo articolo illustra come stimare e gestire i costi per il pool SQL serverless in Azure Synapse Analytics:
- Stimare la quantità di dati elaborati prima di eseguire una query
- Usare la funzionalità di controllo dei costi per impostare il budget
Comprendere che i costi del pool SQL serverless in Azure Synapse Analytics sono solo una parte dei costi mensili nella fattura di Azure. Se si usano altri servizi di Azure, vengono addebitati tutti i servizi e le risorse di Azure usati nella sottoscrizione di Azure, inclusi i servizi di terze parti. Questo articolo illustra come pianificare e gestire i costi per il pool SQL serverless in Azure Synapse Analytics.
Dati elaborati
I dati elaborati sono la quantità di dati archiviati temporaneamente dal sistema durante l'esecuzione di una query. I dati elaborati sono costituiti dalle quantità seguenti:
- Quantità di dati letti dall'archiviazione. Questo importo include:
- Dati letti durante la lettura dei dati.
- I dati vengono letti durante la lettura dei metadati (per i formati di file che contengono metadati, ad esempio Parquet).
- Quantità di dati in risultati intermedi. Questi dati vengono trasferiti tra nodi durante l'esecuzione della query. Include il trasferimento dei dati all'endpoint, in un formato non compresso.
- Quantità di dati scritti nella risorsa di archiviazione. Se si usa CETAS per esportare il set di risultati nell'archiviazione, la quantità di dati scritti viene aggiunta alla quantità di dati elaborati per la parte SELECT di CETAS.
La lettura dei file dall'archiviazione è altamente ottimizzata. Il processo usa:
- Prelettura, che potrebbe comportare un sovraccarico per la quantità di dati letti. Se una query legge un intero file, non è previsto alcun sovraccarico. Se un file viene letto parzialmente, ad esempio nelle query TOP N, un po' più di dati vengono letti utilizzando la prelettura.
- Parser con valori delimitati da virgole (CSV) ottimizzati. Se si usa PARSER_VERSION='2.0' per leggere i file CSV, aumentano leggermente le quantità di dati letti dall'archiviazione. Un parser CSV ottimizzato legge i file in parallelo, in blocchi di dimensioni uguali. I blocchi non contengono necessariamente righe intere. Per assicurarsi che tutte le righe vengano analizzate, il parser CSV ottimizzato legge anche piccoli frammenti di blocchi adiacenti. Questo processo aggiunge una piccola quantità di overhead.
Statistiche
Query Optimizer del pool SQL serverless si basa sulle statistiche per generare piani di esecuzione delle query ottimali. È possibile creare le statistiche manualmente. In caso contrario, il pool SQL serverless li crea automaticamente. In entrambi i casi, le statistiche vengono create eseguendo una query separata che restituisce una colonna specifica a una frequenza di campionamento specificata. Questa query ha una quantità associata di dati elaborati.
Se si esegue la stessa query o qualsiasi altra query che trarrebbe vantaggio dalle statistiche create, le statistiche vengono riutilizzate quando possibile. Non sono presenti dati aggiuntivi elaborati per la creazione di statistiche.
Quando vengono create statistiche per una colonna Parquet, solo la colonna pertinente viene letta dai file. Quando vengono create statistiche per una colonna CSV, i file interi vengono letti e analizzati.
Arrotondamento
La quantità di dati elaborati viene arrotondata fino al MB più vicino per ogni query. Ogni query ha almeno 10 MB di dati elaborati.
Quali dati elaborati non includono
- Metadati a livello di server , ad esempio account di accesso, ruoli e credenziali a livello di server.
- I database che crei nel tuo endpoint. Tali database contengono solo metadati (ad esempio utenti, ruoli, schemi, viste, funzioni con valori di tabella inline [TVFS], stored procedure, credenziali con ambito database, origini dati esterne, formati di file esterni e tabelle esterne).
- Se si usa l'inferenza dello schema, i frammenti di file vengono letti per dedurre i nomi di colonna e i tipi di dati e la quantità di dati letti viene aggiunta alla quantità di dati elaborati.
- Istruzioni DDL (Data Definition Language), ad eccezione dell'istruzione CREATE STATISTICS, perché elabora i dati dall'archiviazione in base alla percentuale di campione specificata.
- Query sui soli metadati.
Riduzione della quantità di dati elaborati
È possibile ottimizzare la quantità di dati per query elaborata e migliorare le prestazioni partizionando e convertendo i dati in un formato compresso basato su colonne come Parquet.
Examples
Si immaginino tre tabelle.
- La tabella population_csv è supportata da 5 TB di file CSV. I file sono organizzati in cinque colonne di dimensioni uguali.
- Nella tabella population_parquet sono presenti gli stessi dati della tabella population_csv. È supportato da 1 TB di file Parquet. Questa tabella è inferiore a quella precedente perché i dati vengono compressi in formato Parquet.
- La tabella very_small_csv è supportata da 100 KB di file CSV.
Query 1: SELECT SUM(population) FROM population_csv
Questa query legge e analizza l'interezza dei file per ottenere i valori per la colonna popolazione. I nodi elaborano frammenti di questa tabella e la somma della popolazione per ogni frammento viene trasferita tra i nodi. La somma finale viene trasferita all'endpoint.
Questa query elabora 5 TB di dati, più un piccolo sovraccarico per trasferire somme di frammenti.
Query 2: SELECT SUM(population) FROM population_parquet
Quando si eseguono query su formati compressi e basati su colonne come Parquet, meno dati vengono letti rispetto alla query 1. Questo risultato viene visualizzato perché il pool SQL serverless legge una singola colonna compressa anziché l'intero file. In questo caso, si leggono 0,2 TB. Le cinque colonne di dimensioni uguali sono 0,2 TB ciascuna. I nodi elaborano frammenti di questa tabella e la somma della popolazione per ogni frammento viene trasferita tra i nodi. La somma finale viene trasferita all'endpoint.
Questa query elabora 0,2 TB di informazioni, più un piccolo sovraccarico per trasferire somme di frammenti.
Query 3: SELECT * FROM population_parquet
Questa query legge tutte le colonne e trasferisce tutti i dati in un formato non compresso. Se il formato di compressione è 5:1, la query elabora 6 TB perché legge 1 TB e trasferisce 5 TB di dati non compressi.
Query 4: SELECT COUNT(*) FROM very_small_csv
Questa query legge tutti i file. La dimensione totale dei file nell'archiviazione per questa tabella è di 100 KB. I nodi elaborano frammenti di questa tabella e la somma per ogni frammento viene trasferita tra i nodi. La somma finale viene trasferita all'endpoint specifico.
Questa query elabora leggermente più di 100 KB di dati. La quantità di dati elaborati per questa query viene arrotondata fino a 10 MB, come specificato nella sezione Arrotondamento di questo articolo.
Controllo costi
La funzionalità di controllo dei costi nel pool SQL serverless consente di impostare il budget per la quantità di dati elaborati. È possibile impostare il budget in TB di dati elaborati per un giorno, una settimana e un mese. Allo stesso tempo è possibile impostare uno o più budget. Per configurare il controllo dei costi per il pool SQL serverless, è possibile usare Synapse Studio o T-SQL.
Configurare il controllo dei costi per il pool serverless SQL in Synapse Studio
Per configurare il controllo dei costi per il pool SQL serverless in Synapse Studio, navigare alla voce Gestisci nel menu a sinistra, quindi selezionare la voce pool SQL in Pool di analisi. Quando si passa il puntatore del mouse sul pool SQL serverless, si noterà un'icona per il controllo dei costi. Fare clic su questa icona.
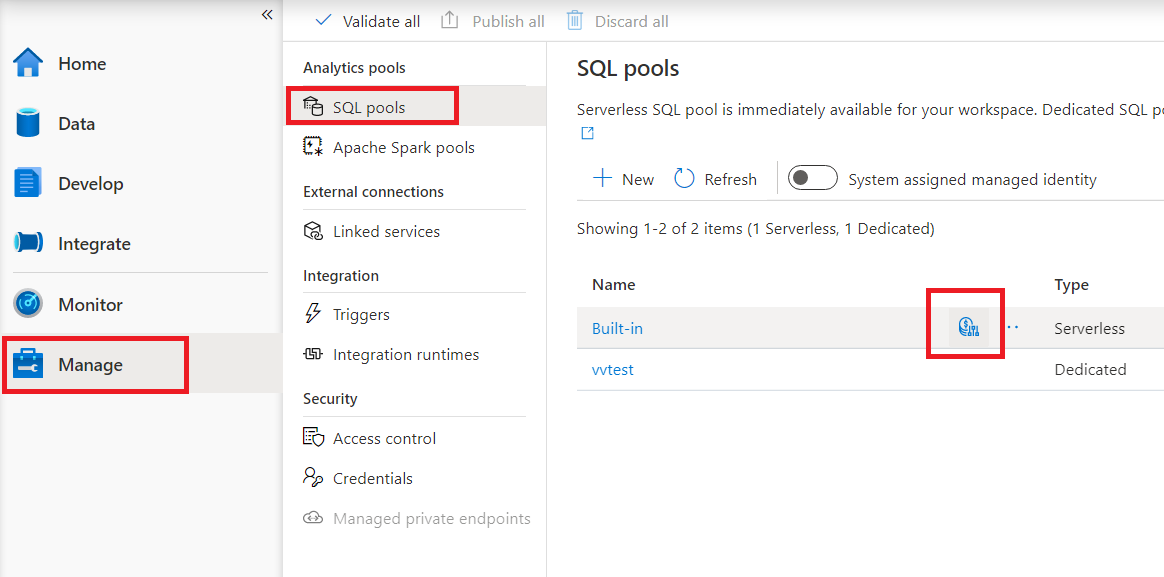
Dopo aver fatto clic sull'icona del controllo dei costi, verrà visualizzata una barra laterale:
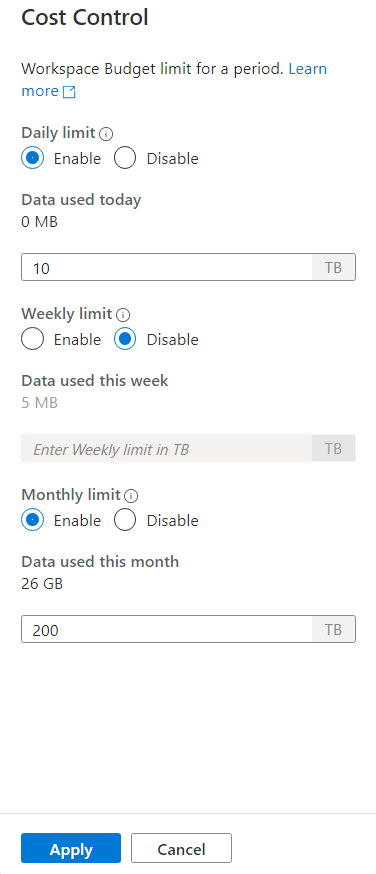
Per impostare uno o più budget, fai prima clic sul pulsante di opzione Abilita per il budget che desideri impostare, quindi immetti il valore intero nella casella di testo. L'unità per il valore è TBS. Dopo aver configurato i budget desiderati, fare clic sul pulsante Applica nella parte inferiore della barra laterale. Ecco, il tuo budget è ora impostato.
Configurare il controllo dei costi per il pool SQL serverless in T-SQL
Per configurare il controllo dei costi per il pool SQL serverless in T-SQL, è necessario eseguire una o più delle seguenti stored procedure.
sp_set_data_processed_limit
@type = N'daily',
@limit_tb = 1
sp_set_data_processed_limit
@type= N'weekly',
@limit_tb = 2
sp_set_data_processed_limit
@type= N'monthly',
@limit_tb = 3334
Per visualizzare la configurazione corrente, eseguire l'istruzione T-SQL seguente:
SELECT * FROM sys.configurations
WHERE name like 'Data processed %';
Per verificare la quantità di dati elaborati durante il giorno, la settimana o il mese corrente, eseguire l'istruzione T-SQL seguente:
SELECT * FROM sys.dm_external_data_processed
Superamento dei limiti definiti nel controllo dei costi
Nel caso in cui un limite venga superato durante l'esecuzione della query, la query non verrà terminata.
Quando il limite definito per quel periodo viene superato, la nuova query verrà rifiutata con un messaggio di errore che contiene i dettagli relativi al periodo, al limite definito per quel periodo e ai dati elaborati in quel periodo. Ad esempio, nel caso in cui venga eseguita una nuova query, in cui il limite settimanale è impostato su 1 TB e viene superato, il messaggio di errore sarà:
Query is rejected because SQL Serverless budget limit for a period is exceeded. (Period = Weekly: Limit = 1 TB, Data processed = 1 TB))
Passaggi successivi
Per informazioni su come ottimizzare le query per le prestazioni, vedere Procedure consigliate per il pool SQL serverless.