Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
Si applica a: App per la logica di Azure (Consumo + Standard)
In alcuni casi è necessario convertire il contenuto in token, ovvero parole o blocchi di caratteri, oppure dividere un documento di grandi dimensioni in parti più piccole prima di poter usare questo contenuto con azioni specifiche. Ad esempio, le azioni Azure AI Search o Azure OpenAI prevedono input con token e possono gestire solo un numero limitato di token.
Per questi scenari, usare le azioni di Operazioni dati denominate Analizzare un documento e Suddividere testo in blocchi nel flusso di lavoro dell'app per la logica. Queste azioni trasformano rispettivamente il contenuto, ad esempio un documento PDF, un file CSV, un file Excel e così via, in una stringa tokenizzata e quindi suddivide la stringa in parti, in base al numero di token. È possibile quindi fare riferimento e usare questi output con le azioni successive previste dal flusso di lavoro.
Suggerimento
Per altre informazioni, è possibile porre Azure Copilot queste domande:
- Che cos'è un token nell'intelligenza artificiale?
- Che cos'è l'input con token?
- Che cos'è l'output di stringa con token?
- Che cos'è l'analisi nell’intelligenza artificiale?
- Che cos'è la suddivisione in blocchi nell'intelligenza artificiale?
Per trovare Azure Copilot, nella barra degli strumenti Azure portal selezionare Copilot.
Questa guida illustra come aggiungere e configurare azioni per l'analisi dei documenti e la suddivisione in blocchi del flusso di lavoro.
Problemi noti e limitazioni
Nei flussi di lavoro a consumo l'azione Parse un documento è disponibile solo nelle aree Azure seguenti:
- Australia orientale
- Brasile meridionale
- Asia orientale
- Stati Uniti orientali
- Stati Uniti orientali 2
- North Europe
- Stati Uniti centro-meridionali
- Sud-est asiatico
- Svezia centrale
- West US 2 (Regione Ovest degli Stati Uniti 2)
- Stati Uniti occidentali 3
- UK South
Queste regioni forniscono connessioni all'origine dati, tracciamento dei documenti, suddivisione dei documenti, supporto per i modelli di incorporamento di Azure OpenAI e supporto predefinito per l'indicizzazione per l'estrazione dei dati. Per altre informazioni, vedere Indicizzazione automatica in Ricerca di intelligenza artificiale con flussi di lavoro in App per la logica di Azure.
Le azioni Analizzare un documento e Suddividere testo in blocchi non supportano attualmente file host come i file binari mainframe e di fascia intermedia, ad esempio i file VSAM (Virtual Storage Access Method). Tuttavia, se si usano flussi di lavoro Standard, è possibile usare l'azione predefinita IBM Host File denominata Analizza contenuto file host.
Prerequisiti
Un account e una sottoscrizione Azure. Se non si ha una sottoscrizione Azure, iscriversi per ottenere un account Azure gratuito.
Un flusso di lavoro dell'app per la logica A consumo o Standard con un trigger esistente perché le operazioni Analizzare un documento e Suddividere testo in blocchi sono disponibili solo come azioni. Assicurarsi che l'azione che recupera il contenuto da analizzare o da suddividere in blocchi preceda queste operazioni sui dati.
Analizzare un documento
L'azione Parse un documento converte il contenuto, ad esempio un documento PDF, un file CSV, Excel file e così via, in una stringa con token. Per questo esempio, si supponga che il flusso di lavoro inizi con il trigger Di richiesta denominato Quando viene ricevuta una richiesta HTTP. Questo trigger attende di ricevere una richiesta HTTP inviata da un altro componente, ad esempio una funzione Azure, un altro flusso di lavoro dell'app per la logica e così via. La richiesta HTTP include l'URL di un nuovo documento caricato disponibile per essere recuperato e analizzato dal flusso di lavoro. Un'azione HTTP segue immediatamente il trigger, invia una richiesta HTTP all'URL del documento e restituisce il contenuto del documento dalla relativa posizione di archiviazione.
Se si usano altre origini di contenuto, ad esempio Archiviazione BLOB di Azure, SharePoint, OneDrive, file system, FTP e così via, è possibile verificare se i trigger sono disponibili per queste origini. È possibile verificare anche se sono disponibili azioni per recuperare il contenuto di queste origini. Per altre informazioni, vedere Operazioni predefinite e Connettori gestiti.
Nel portale Azure, apri la risorsa della tua logic app e il flusso di lavoro nel designer.
Nel trigger e nelle azioni esistenti, seguire questa procedura generale per aggiungere l'azione di Operazioni dati denominata Analizzare un documento al flusso di lavoro.
Nella finestra di progettazione selezionare l'azione Analizzare un documento.
Quando si apre il riquadro delle informazioni dell'azione, nella scheda Parametri, in corrispondenza della proprietà Contenuto del documento specificare il contenuto da analizzare seguendo questa procedura:
Selezionare all'interno della casella Contenuto del documento.
Vengono visualizzate le opzioni per l'elenco di contenuto dinamico (icona a forma di fulmine) e per l'editor di espressioni (icona della funzione).
Per scegliere l'output da un'azione precedente, selezionare l'elenco di contenuto dinamico.
Per creare un'espressione che modifichi l'output da un'azione precedente, selezionare l'editor di espressioni.
Questo esempio continua selezionando l'icona a forma di fulmine per l'elenco di contenuto dinamico.
Quando si apre il riquadro delle informazioni dell'azione, selezionare l'output desiderato da un'operazione precedente.
In questo esempio, l'azione Analizzare un documento fa riferimento all'output Corpo dell'azione HTTP.

L'output Corpo viene ora visualizzato nella casella Contenuto del documento:
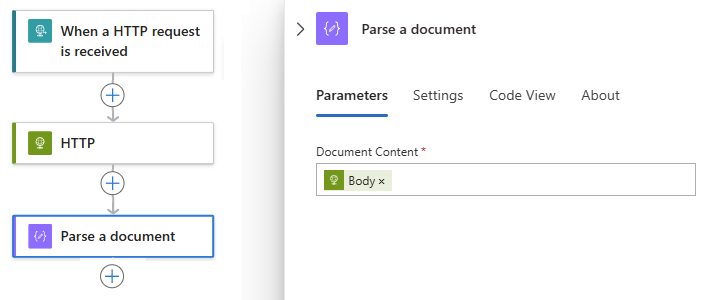
Nell'azione Analizzare un documento aggiungere le azioni che si desidera usare con l'output di stringa con token, ad esempio Suddividere testo in blocchi, descritto più avanti in questa guida.
Analizzare un documento - Riferimento
Parametri
| Nome | valore | Tipo di dati | Descrizione | Limite |
|---|---|---|---|---|
| Contenuto del documento | < contenuto da analizzare> | Qualsiasi | Contenuto da analizzare. | nessuno |
Output
| Nome | Tipo di dati | Descrizione |
|---|---|---|
| Testo del risultato analizzato | Matrice di stringhe | Matrice di stringhe. |
| Risultato analizzato | Oggetto | Oggetto che contiene l'intero testo analizzato. |
Suddividere testo in blocchi
L'azione Suddividere testo in blocchi suddivide il contenuto in parti più piccole, in modo da poter essere usato più facilmente nelle azioni successive del flusso di lavoro corrente. I passaggi seguenti si basano sull'esempio della sezione Parse un documento e suddivide l'output della stringa del token da usare con operazioni di intelligenza artificiale Azure che prevedono blocchi di contenuto di piccole dimensioni con token.
Note
Eventuali azioni precedenti in cui è stata usata la suddivisione in blocchi non influiscono sull'azione Suddividere testo in blocchi, né l’azione Suddividere testo in blocchi influisce sulle azioni successive in cui verrà usata la suddivisione in blocchi.
Nel portale Azure aprire la risorsa e il flusso di lavoro dell'app per la logica nella finestra di progettazione.
Nell'azione Analizzare un documento, seguire questa procedura generale per aggiungere l'azione di Operazioni dati denominata Suddividere testo in blocchi.
Nella finestra di progettazione selezionare l'azione Suddividere testo in blocchi.
Quando si apre il riquadro delle informazioni dell'azione, nella scheda Parametri, in corrispondenza della proprietà Strategia di suddivisione in blocchi, selezionare TokenSize come metodo di suddivisione in blocchi, se non è già selezionato.
Strategia Descrizione TokenSize Suddividere il contenuto specificato in base al numero di token. Dopo aver selezionato la strategia, selezionare all'interno della casella Testo per specificare il contenuto per la suddivisione in blocchi.
Vengono visualizzate le opzioni per l'elenco di contenuto dinamico (icona a forma di fulmine) e per l'editor di espressioni (icona della funzione).
Per scegliere l'output da un'azione precedente, selezionare l'elenco di contenuto dinamico.
Per creare un'espressione che modifichi l'output da un'azione precedente, selezionare l'editor di espressioni.
Questo esempio continua selezionando l'icona a forma di fulmine per l'elenco di contenuto dinamico.
Quando si apre il riquadro delle informazioni dell'azione, selezionare l'output desiderato da un'operazione precedente.
In questo esempio, l'azione Suddividere testo in blocchi fa riferimento all’output Testo del risultato analizzato generato dall'azione Analizzare un documento.

La casella Testo mostra ora l'output dell'azione Risultato analizzato:

Completare la configurazione dell'azione Suddividere testo in blocchi in base alla strategia e allo scenario selezionati. Per altre informazioni, vedere Suddividere testo in blocchi - Riferimento.
Ora, quando si aggiungono altre azioni che prevedono e usano input con token, ad esempio le azioni di intelligenza artificiale Azure, il contenuto di input viene formattato per un utilizzo più semplice.
Suddividere testo in blocchi - Riferimento
Parametri
| Nome | valore | Tipo di dati | Descrizione | Limiti |
|---|---|---|---|---|
| Strategia di suddivisione in blocchi | TokenSize | Enum stringa | Suddivide il contenuto in base al numero di token. Impostazione predefinita: TokenSize |
Non applicabile |
| Text | < content-to-chunk> | Qualsiasi | Contenuto da suddividere in blocchi. | Vedere Guida di riferimento ai limiti e alla configurazione |
| EncodingModel | < encoding-method> | Enum stringa | Modello di codifica da usare: - Impostazione predefinita: cl100k_base (gpt4, gpt-3.5-turbo, gpt-35-turbo) - r50k_base (gpt-3) - p50k_base (gpt-3) - p50k_edit (gpt-3) - cl200k_base (gpt-4o) Per altre informazioni, vedere Panoramica di OpenAI - Modelli. |
Non applicabile |
| TokenSize | < max-tokens-per-chunk> | Integer | Numero massimo di token per blocco di contenuto. Impostazione predefinita: nessuna |
Minimo: 1 Massimo: 8000 |
| PageOverlapLength | < numero di caratteri sovrapposti> | Integer | Numero di caratteri da copiare dalla fine del blocco precedente e includere nel blocco successivo. Questa impostazione consente di evitare di perdere informazioni importanti durante la suddivisione del contenuto in blocchi e mantiene la continuità e il contesto tra i blocchi. Impostazione predefinita: 0 - Nessun carattere sovrapposto. |
Minimo: 0 |
Suggerimento
Per altre informazioni, è possibile porre Azure Copilot queste domande:
- Che cos'è PageOverlapLength nella suddivisione in blocchi?
- Che codifica è in Azure AI?
Per trovare Azure Copilot, nella barra degli strumenti Azure portal selezionare Copilot.
Output
| Nome | Tipo di dati | Descrizione |
|---|---|---|
| Elementi di testo del risultato in blocchi | Matrice di stringhe | Matrice di stringhe. |
| Elemento di testo del risultato in blocchi | string | Singola stringa nella matrice. |
| Risultato in blocchi | Oggetto | Oggetto contenente l'intero testo suddiviso in blocchi. |
Esempio di flusso di lavoro
L'esempio seguente include altre azioni che danno origine a un modello di flusso di lavoro completo per inserire dati da qualsiasi origine:
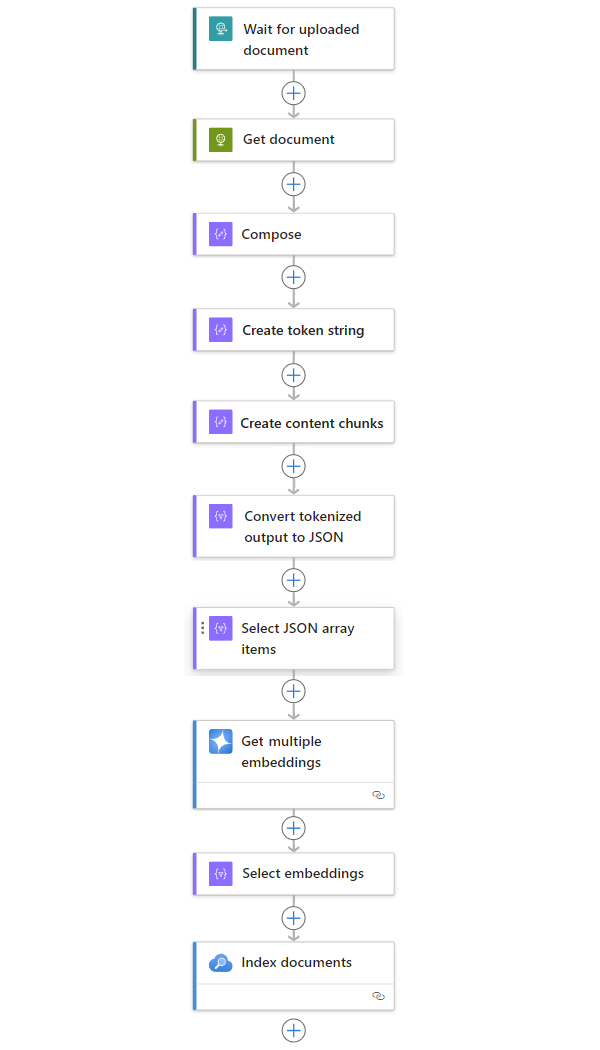
| Passaggio | Attività | Operazione sottostante | Descrizione |
|---|---|---|---|
| 1 | Attendere o controllare la presenza di nuovo contenuto. | Quando viene ricevuta una richiesta HTTP | Un trigger che esegue il polling o attende l'arrivo di nuovi dati, rispettivamente basato su una ricorrenza pianificata o in risposta a eventi specifici. Un evento di questo tipo potrebbe essere un nuovo file caricato in un sistema di archiviazione specifico, ad esempio Archiviazione BLOB di Azure, SharePoint, OneDrive, file system, FTP e così via. In questo esempio, l'operazione di trigger Richiesta attende una richiesta HTTP o HTTPS inviata da un altro endpoint. La richiesta include l'URL di un nuovo documento caricato. |
| 2 | Ottenere il contenuto. | HTTP | Un’azione HTTP che recupera il documento caricato usando l'URL del file presente nell'output del trigger. |
| 3 | Comporre i dettagli del documento. | Componi | Un’azione di Operazioni dati che concatena vari elementi. In questo esempio vengono concatenate informazioni di tipo chiave-valore sul documento. |
| 4 | Creare la stringa token. | Analizzare un documento | Un'azione di Operazioni dati che produce una stringa con token usando l'output dell'azione Componi. |
| 5 | Creare blocchi di contenuto. | Testo blocco | Un'azione di Operazioni dati che suddivide la stringa del token in più parti, in base al numero di token per ogni blocco di contenuto. |
| 6 | Convertire il testo con token e in blocchi in formato JSON. | Analizza JSON | Un'azione Operazioni dati che converte l'output in blocchi in una matrice JSON. |
| 7 | Selezionare elementi della matrice JSON. | Select | Un'azione di Operazioni dati che seleziona più elementi dalla matrice JSON. |
| 8 | Generare gli incorporamenti. | Ottenere più incorporamenti | Azione Azure OpenAI che crea incorporamenti per ogni elemento della matrice JSON. |
| 9 | Selezionare incorporamenti e altre informazioni. | Select | Un'azione delle Operazioni dati che seleziona incorporamenti e altre informazioni sul documento. |
| 10 | Indicizzare i dati. | Indicizzare i documenti | Azione Azure AI Search che indicizza i dati in base a ogni incorporamento selezionato. |