Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
SI APPLICA A: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Suggerimento
Cercare un modo semplice per spostare i dati? Il processo di copia in Microsoft Fabric offre un modo semplice e scalabile per caricare i dati senza creare una pipeline. Informazioni su come crearne uno.
In questa esercitazione si usa il portale di Azure per creare una data factory. Viene quindi usato lo strumento Copia dati per creare una pipeline che copia i dati da un archivio BLOB di Azure a un database SQL.
Nota
Se non si ha familiarità con Azure Data Factory, vedere Introduzione ad Azure Data Factory.
In questa esercitazione si segue questa procedura:
- Creare una data factory.
- Usare lo strumento Copia dati per creare una pipeline.
- Monitorare le esecuzioni di pipeline e attività.
Prerequisiti
- Sottoscrizione di Azure: se non si ha una sottoscrizione di Azure, creare un account gratuito prima di iniziare.
- Account di archiviazione di Azure: usare l'archiviazione BLOB come archivio dati di origine. Se non è disponibile un account di archiviazione di Azure, vedere le istruzioni fornite in Creare un account di archiviazione.
- Database SQL di Azure: usare un database SQL come archivio dati sink. Se non si ha un database SQL, vedere le istruzioni in Creare un database SQL.
Preparare il database SQL
Consentire ai servizi di Azure di accedere al server SQL logico del database SQL di Azure.
Verificare che per il server che esegue il database SQL sia abilitata l'impostazione Consenti ai servizi di Azure di accedere al server, Questa impostazione consente a Data Factory di scrivere dati nell'istanza di database. Per verificare e attivare questa impostazione, andare su Sicurezza > Firewall e reti virtuali > per SQL Server logici > e impostare l'opzione Consenti ai servizi e alle risorse di Azure di accedere a questo server su ON.
Nota
L'opzione Consenti ai servizi e alle risorse di Azure di accedere a questo server consente l'accesso di rete a SQL Server da qualsiasi risorsa di Azure, non solo a quelli nella sottoscrizione. Potrebbe non essere appropriato per tutti gli ambienti, ma è appropriato per questa esercitazione limitata. Per altre informazioni, vedere Regole del firewall di SQL Server di Azure. È invece possibile usare endpoint privati per connettersi ai servizi PaaS di Azure senza usare indirizzi IP pubblici.
Creare un BLOB e una tabella SQL
Preparare l'archivio BLOB e il database SQL per l'esercitazione seguendo questa procedura.
Creare un blob di origine
Avviare il Blocco note. Copiare il testo seguente e salvarlo in un file denominato inputEmp.txt sul disco:
FirstName|LastName John|Doe Jane|DoeCreare un contenitore denominato adfv2tutorial e caricare il file inputEmp.txt nel contenitore. Per eseguire queste attività è possibile usare il portale di Azure o vari strumenti, ad esempio Azure Storage Explorer.
Creare una tabella SQL sink
Usare lo script SQL seguente per creare una tabella denominata
dbo.empnel database SQL:CREATE TABLE dbo.emp ( ID int IDENTITY(1,1) NOT NULL, FirstName varchar(50), LastName varchar(50) ) GO CREATE CLUSTERED INDEX IX_emp_ID ON dbo.emp (ID);
Crea una fabbrica di dati
Nel menu in alto selezionare Crea una risorsa>Data Factory>:

Nella pagina Nuova data factory, sotto Nome, immettere ADFTutorialDataFactory.
Il nome della data factory deve essere univoco a livello globale. Potrebbe essere visualizzato il messaggio di errore seguente:

Se viene visualizzato un messaggio di errore relativo al valore del nome, immettere un nome diverso per la data factory. Ad esempio, usare il nome nomeutenteADFTutorialDataFactory. Per informazioni sulle regole di denominazione per gli elementi di Data Factory, vedere Azure Data Factory - Regole di denominazione.
Selezionare la sottoscrizione di Azure in cui creare la nuova data factory.
In Gruppo di risorse eseguire una di queste operazioni:
a) Selezionare Usa esistentee scegliere un gruppo di risorse esistente dall'elenco a discesa.
b. Selezionare Crea nuovoe immettere un nome per il gruppo di risorse.
Per informazioni sui gruppi di risorse, vedere l'articolo su come usare gruppi di risorse per gestire le risorse di Azure.
In Versione selezionare la versione V2.
In Località, selezionare la località per la fabbrica dati. Nell'elenco a discesa vengono visualizzate solo le località supportate. Gli archivi dati (ad esempio, Archiviazione di Azure e il database SQL) e le risorse di calcolo (ad esempio, Azure HDInsight) usati dalla data factory possono trovarsi in altre località e aree.
Seleziona Crea.
Al termine della creazione verrà visualizzata la home page Data factory.

Per avviare l'interfaccia utente di Azure Data Factory in una scheda separata, selezionare Apri nel riquadro Apri Azure Data Factory Studio.
Usare lo strumento Copia dati per creare una pipeline
Nella home page di Azure Data Factory selezionare il riquadro Inserimento per avviare lo strumento Copia dati.

Nella pagina Proprietà dello strumento Copia dati scegliere Attività di copia predefinita in Tipo di attività e quindi selezionare Avanti.

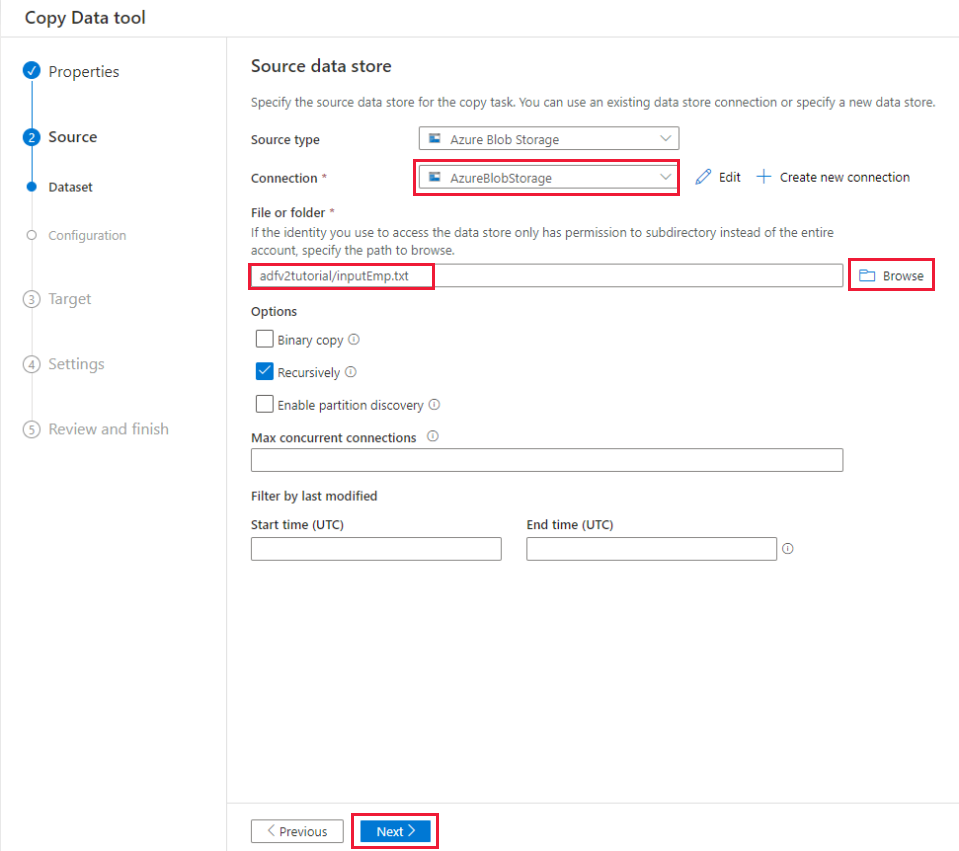
Nella pagina Archivio dati di origine completare la procedura seguente:
a) Selezionare + Crea nuova connessione per aggiungere una connessione.
b. Selezionare Archiviazione BLOB di Azure nella raccolta e quindi Continua.
c. Nella pagina Nuova connessione (Archiviazione BLOB di Azure), selezionare la sottoscrizione di Azure dall'elenco sottoscrizioni di Azure e selezionare il nome dell'account di archiviazione dall'elenco account di archiviazione. Testare la connessione e quindi selezionare Crea.
d. Selezionare il servizio collegato appena creato come origine nel blocco Connessione .
e. Nella sezione File o cartella selezionare Sfoglia per passare alla cartella adfv2tutorial, selezionare il file inputEmp.txt, quindi selezionare OK.
f. Selezionare Avanti per passare al passaggio successivo.
Nella pagina Impostazioni del formato di file abilitare la casella di controllo Prima riga come intestazione. Si noti che lo strumento rileva automaticamente i delimitatori di colonna e di riga ed è possibile visualizzare in anteprima i dati e visualizzare lo schema dei dati di input selezionando il pulsante Anteprima dati in questa pagina. Quindi seleziona Avanti.

Nella pagina archivio dati di destinazione completare la procedura seguente:
a) Selezionare + Crea nuova connessione per aggiungere una connessione.
b. Selezionare Database SQL di Azure dalla raccolta e quindi fare clic su Continua.
c. Nella pagina Nuova connessione (database SQL di Azure) selezionare la sottoscrizione di Azure, il nome del server e il nome del database dall'elenco a discesa. Poi selezionare Autenticazione SQL sotto Tipo di autenticazione, specificare il nome utente e la password. Testare la connessione e selezionare Crea.

d. Selezionare il servizio collegato appena creato come sink, quindi selezionare Avanti.
Nella pagina Archivio dati di destinazione selezionare Usa tabella esistente e selezionare la tabella
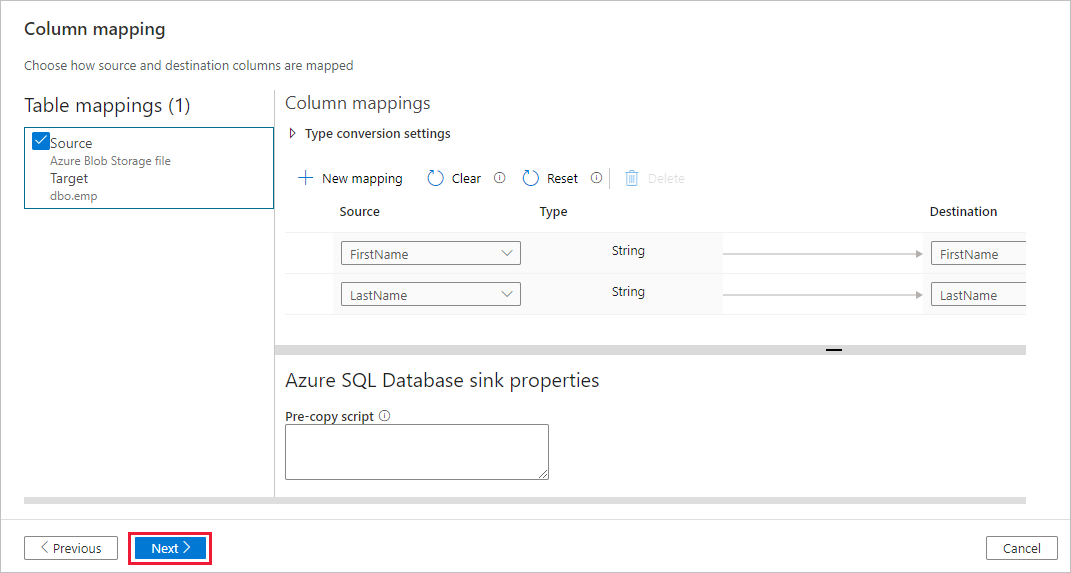
dbo.emp. Quindi seleziona Avanti.Nella pagina Mapping colonne si noti che la seconda e la terza colonna del file di input sono mappate alle colonne FirstName e LastName della tabella emp. Modificare il mapping per verificare che non siano presenti errori, quindi selezionare Avanti.
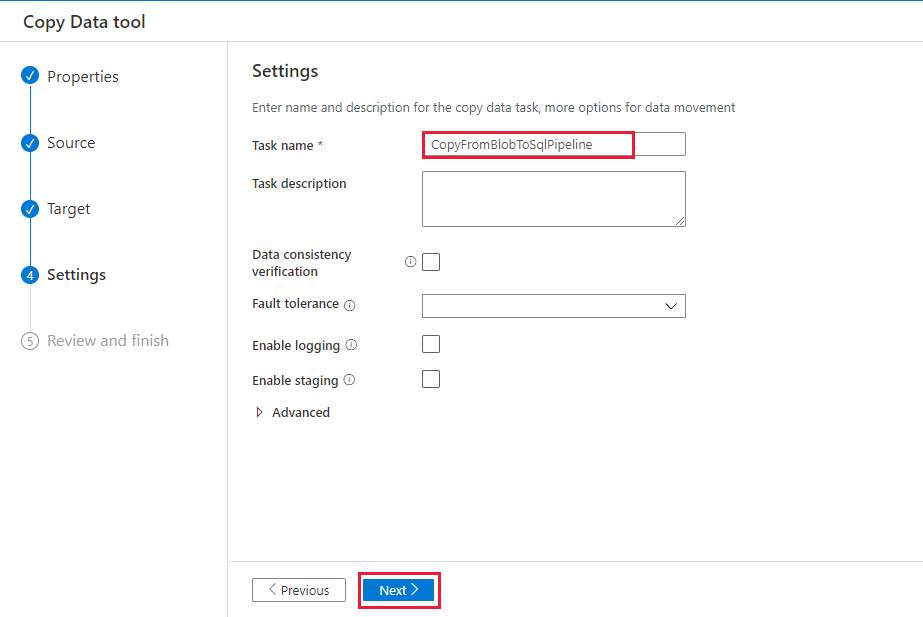
Nella pagina Impostazioni, in Nome attività immettere CopyFromBlobToSqlPipeline e quindi selezionare Avanti.
Nella pagina Riepilogo esaminare le impostazioni e quindi selezionare Avanti.
Nella pagina Distribuzione selezionare Monitoraggio per monitorare la pipeline (attività).

Nella pagina Esecuzioni della pipeline selezionare Aggiorna per aggiornare l'elenco. Selezionare il collegamento sotto Nome pipeline per visualizzare i dettagli di esecuzione dell'attività o rieseguire la pipeline.

Nella pagina "Esecuzioni attività", selezionare il collegamento Dettagli (icona occhiali) nella colonna Nome attività per altri dettagli sull'operazione di copia. Per tornare alla vista "Esecuzioni pipeline", selezionare il collegamento Tutte le esecuzioni della pipeline nel menu di navigazione. Per aggiornare la visualizzazione, selezionare Aggiorna.

Verificare che i dati siano inseriti nella tabella dbo.emp del database SQL.
Selezionare la scheda Autore a sinistra per passare alla modalità di modifica. L'editor consente di aggiornare i servizi collegati, i set di dati e le pipeline che sono stati creati tramite lo strumento. Per informazioni dettagliate sulla modifica di queste entità nell'interfaccia utente di Data Factory, consultare la versione di questa esercitazione nel portale di Azure.

Contenuto correlato
La pipeline di questo esempio copia i dati da un archivio BLOB a un database SQL. Si è appreso come:
- Creare una data factory.
- Usare lo strumento Copia dati per creare una pipeline.
- Monitorare le esecuzioni di pipeline e attività.
Passare all'esercitazione successiva per informazioni sulla copia di dati dall'ambiente locale al cloud: