Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
APPLICABILE A: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Suggerimento
Data Factory in Microsoft Fabric è la nuova generazione di Azure Data Factory, con un'architettura più semplice, un'intelligenza artificiale predefinita e nuove funzionalità. Se non si ha familiarità con l'integrazione dei dati, iniziare con Fabric Data Factory. I carichi di lavoro di Azure Data Factory esistenti possono eseguire l'aggiornamento a Fabric per accedere a nuove funzionalità tra data science, analisi in tempo reale e creazione di report.
In questa esercitazione si usa il portale di Azure per creare una data factory. Usare quindi lo strumento Copy Data per creare una pipeline che copia i dati da un database SQL Server all'archiviazione BLOB di Azure.
Nota
- Se non si ha familiarità con Azure Data Factory, vedere Introduzione a Data Factory.
In questa esercitazione si segue questa procedura:
- Creare una fabbrica di dati.
- Usare lo strumento Copia dati per creare una pipeline.
- Monitora le esecuzioni delle pipeline e delle attività.
Prerequisiti
sottoscrizione Azure
Prima di iniziare, se non si ha già una sottoscrizione Azure, creare un account gratuito.
ruoli Azure
Per creare istanze di Data Factory, all'account utente usato per accedere a Azure deve essere assegnato un ruolo Contributor o Owner o deve essere un ruolo administrator della sottoscrizione Azure.
Per visualizzare le autorizzazioni disponibili nella sottoscrizione, passare al portale di Azure. Selezionare il nome utente nell'angolo superiore destro e quindi Autorizzazioni. Se si accede a più sottoscrizioni, selezionare quella appropriata. Per istruzioni di esempio su come aggiungere un utente a un ruolo, vedere Assegnare ruoli Azure usando il portale di Azure.
SQL Server 2014, 2016 e 2017
In questa esercitazione si usa un database SQL Server come archivio dati source. La pipeline nella data factory creata in questa esercitazione copia i dati da questo database SQL Server (origine) all'archivio BLOB (sink). Creare quindi una tabella denominata emp nel database di SQL Server e inserire un paio di voci di esempio nella tabella.
Avviare SQL Server Management Studio. Se non è già installato nel computer, passare a Scaricare SQL Server Management Studio.
Connettersi all'istanza di SQL Server usando le credenziali.
Creare un database di esempio. Nella visualizzazione struttura ad albero fare clic con il pulsante destro del mouse su Database e scegliere Nuovo database.
Nella finestra Nuovo database immettere un nome per il database e fare clic su OK.
Per creare la tabella emp e inserirvi alcuni dati di esempio, eseguire questo script di query sul database. Nella visualizzazione struttura ad albero fare clic con il pulsante destro del mouse sul database creato e scegliere Nuova query.
CREATE TABLE dbo.emp ( ID int IDENTITY(1,1) NOT NULL, FirstName varchar(50), LastName varchar(50) ) GO INSERT INTO emp (FirstName, LastName) VALUES ('John', 'Doe') INSERT INTO emp (FirstName, LastName) VALUES ('Jane', 'Doe') GO
account di archiviazione Azure
In questa esercitazione si usa un account di archiviazione generale di Azure, in particolare archiviazione di BLOB, come archivio dati di destinazione. Se non si ha un account di archiviazione per utilizzo generico, vedere Creare un account di archiviazione per istruzioni su come crearne uno. La pipeline che crei nella fabbrica di dati in questa esercitazione copia i dati dal database SQL Server (origine) a questo archivio BLOB (sink).
Ottieni il nome e la chiave dell'account di archiviazione
In questa esercitazione si usano il nome e la chiave dell'account di archiviazione. Per recuperare il nome e la chiave dell'account di archiviazione, seguire questa procedura:
Accedere al portale Azure portale con il nome utente e la password Azure.
Nel riquadro sinistro selezionare Tutti i servizi. Usare la parola chiave Archiviazione come filtro e quindi selezionare Account di archiviazione.

Nell'elenco degli account di archiviazione filtrare, se necessario, il proprio account di archiviazione. Selezionare quindi l'account di archiviazione.
Nella finestra Account di archiviazione selezionare Chiavi di accesso.
Nelle caselle Nome account di archiviazione e key1 copiare i valori e incollarli nel Blocco note o in un altro editor per usarli in seguito nell'esercitazione.
Creare una data factory
Nel menu in alto selezionare Crea una risorsa>Data Factory>:

Nella pagina Nuova data factory, sotto Nome, immettere ADFTutorialDataFactory.
Il nome della data factory deve essere univoco a livello globale. Se viene visualizzato il messaggio di errore seguente per il campo Nome, modificare il nome della data factory, ad esempio usando nomeutenteADFTutorialDataFactory. Per informazioni sulle regole di denominazione per gli elementi di Data factory, vedere Azure Data factory - Regole di denominazione.
Messaggio di errore della data factory per nome duplicato.
Selezionare la sottoscrizione di Azure subscription in cui si vuole creare la fabbrica di dati.
In Gruppo di risorse eseguire una di queste operazioni:
Selezionare Usa esistentee scegliere un gruppo di risorse esistente dall'elenco a discesa.
Selezionare Crea nuovoe immettere un nome per il gruppo di risorse.
Per informazioni sui gruppi di risorse, vedere Usare i gruppi di risorse per gestire le risorse Azure.
In Versione selezionare V2.
In Località selezionare la località per la data factory. Nell'elenco a discesa vengono mostrate solo le località supportate. Gli archivi dati (ad esempio, Archiviazione di Azure e il database SQL) e i calcoli (ad esempio, Azure HDInsight) usati da Data Factory possono trovarsi in altre posizioni/aree.
Seleziona Crea.
Al termine della creazione verrà visualizzata la pagina Data factory, come illustrato nell'immagine.
pagina principale di Azure Data Factory, con il riquadro Apri Azure Data Factory Studio.
Selezionare Open nel riquadro Open Azure Data Factory Studio per avviare l'interfaccia utente di Data Factory in una scheda separata.
Usare lo strumento Copia dati per creare una pipeline
Nella home page Azure Data Factory selezionare Ingest per avviare lo strumento Copia dati.

Nella pagina Proprietà dello strumento Copia dati scegliere Attività di copia predefinita in Tipo di attività e scegliere Esegui una sola volta in Frequenza attività o pianificazione attività, quindi selezionare Avanti.
Nella pagina Archivio dati di origine selezionare + Crea nuova connessione.
In Nuova connessione cercare SQL Server e quindi selezionare Continue.
Nella finestra di dialogo Nuova connessione (SQL Server) in Nome immettere SqlServerLinkedService. Selezionare +Nuovo sotto Connect via integration runtime (Connettersi tramite runtime di integrazione). È necessario creare un runtime di integrazione self-hosted, scaricarlo nel computer e registrarlo in Data Factory. Il runtime di integrazione self-hosted copia i dati tra l'ambiente in locale e il cloud.
Nella finestra di dialogo Configurazione del runtime di integrazione selezionare Self-Hosted. Selezionare Continua.
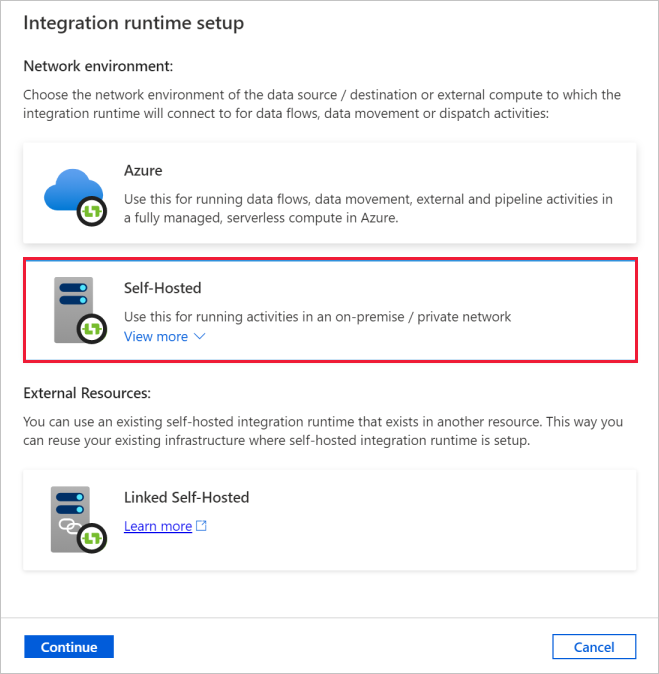
Nella finestra di dialogo Configurazione del runtime di integrazione, in Nome, immettere TutorialIntegrationRuntime. Selezionare Crea.
Nella finestra di dialogo Integration Runtime setup (Configurazione del runtime di integrazione) selezionare Fare clic qui per avviare l'installazione rapida per questo computer. Questa azione installa il runtime di integrazione nel computer e lo registra in Data Factory. In alternativa è possibile usare l'opzione di installazione manuale per scaricare il file di installazione, eseguirlo e usare la chiave per registrare il runtime di integrazione.
Eseguire l'applicazione scaricata. In questa finestra viene visualizzato lo stato dell'installazione rapida.

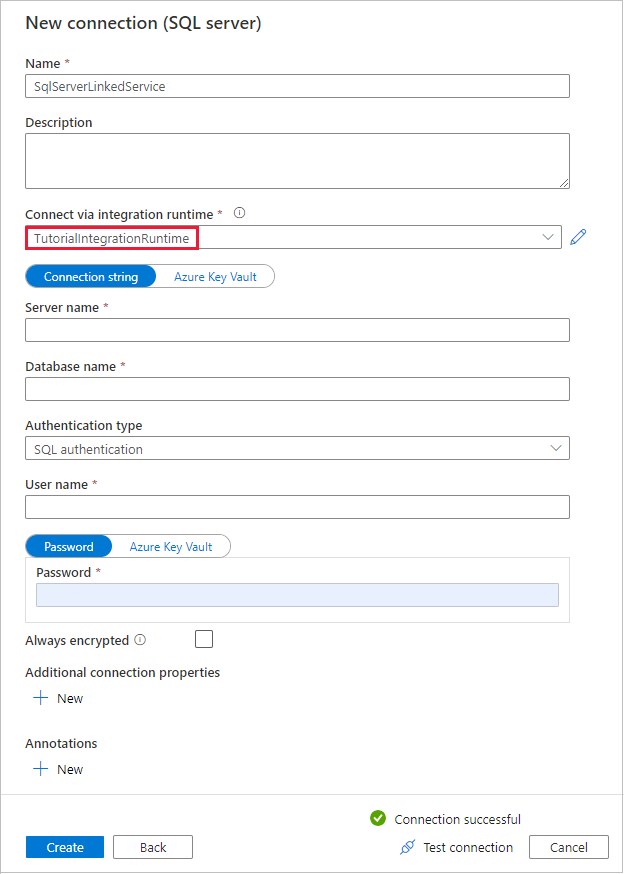
Nella finestra di dialogo Nuova connessione (SQL Server) verificare che TutorialIntegrationRuntime sia selezionato in Connect via integration runtime. Seguire quindi questa procedura:
a) In Nome immettere SqlServerLinkedService.
b. In Nome server immettere il nome dell'istanza di SQL Server.
c. In Nome database immettere il nome del database locale.
d. In Tipo di autenticazione selezionare l'autenticazione appropriata.
e. In Nome utente immettere il nome dell'utente con accesso a SQL Server.
f. Immettere la password per l'utente.
g. Testare la connessione e selezionare Crea.
Nella pagina Origine dati verificare che la connessione SQL Server appena creata sia selezionata nel blocco Connection. Nella sezione Tabelle di origine scegliere TABELLE ESISTENTI, quindi selezionare la tabella dbo.emp nell'elenco e selezionare Avanti. È possibile selezionare qualsiasi altra tabella a seconda del database.
Nella pagina Applica filtro è possibile visualizzare in anteprima i dati e visualizzare lo schema dei dati di input selezionando il pulsante Anteprima dati. Quindi seleziona Avanti.
Nella pagina Archivio dati di destinazione selezionare + Crea nuova connessione
In Nuova connessione cercare e selezionare Archiviazione BLOB di Azure e quindi selezionare Continue.

Nella finestra di dialogo Nuova connessione (Archiviazione BLOB di Azure) seguire questa procedura:
a) In Nome immettere AzureStorageLinkedService.
b. In Connetti tramite il runtime di integrazione, selezionare TutorialIntegrationRuntime e seleziona Chiave account sotto Metodo di autenticazione.
c. In Azure sottoscrizione selezionare la sottoscrizione Azure dall'elenco a discesa.
d. In Nome account di archiviazione selezionare il proprio account di archiviazione nell'elenco a discesa.
e. Testare la connessione e selezionare Crea.
Nella finestra di dialogo Destination data store verificare che la connessione Archiviazione BLOB di Azure appena creata sia selezionata nel blocco Connection. Quindi, su Percorso cartella, immettere adftutorial/fromonprem. Come parte dei prerequisiti è stato creato il contenitore adftutorial. Se la cartella di output (in questo caso fromonprem) non esiste, Data Factory la crea automaticamente. È anche possibile usare il pulsante Sfoglia per passare all'archivio BLOB e ai relativi contenitori/cartelle. Se non si specifica alcun valore in Nome file, per impostazione predefinita viene usato il nome dell'origine (in questo caso dbo.emp).

Nella finestra di dialogo File format settings (Impostazioni formato file) selezionare Avanti.
Nella finestra di dialogo Impostazioni , in Nome attività immettere CopyFromOnPremSqlToAzureBlobPipeline e quindi selezionare Avanti. Lo strumento Copia dati crea una pipeline con il nome specificato per questo campo.
Nella finestra di dialogo Riepilogo esaminare i valori di tutte le impostazioni e selezionare Avanti.
Nella pagina Distribuzione selezionare Monitoraggio per monitorare la pipeline (attività).
Al termine dell'esecuzione della pipeline, è possibile visualizzare lo stato della pipeline che hai creato.
Nella pagina "Esecuzioni pipeline" selezionare Aggiorna per aggiornare l'elenco. Selezionare il collegamento sotto Nome della pipeline per visualizzare i dettagli dell'esecuzione dell'attività o rieseguire la pipeline.

Nella pagina "Esecuzioni attività", selezionare il collegamento Dettagli (icona occhiali) nella colonna Nome attività per ulteriori dettagli sull'operazione di copia. Per tornare alla pagina "Esecuzioni pipeline", selezionare il collegamento Tutte le esecuzioni della pipeline nel menu di navigazione. Per aggiornare la visualizzazione, selezionare Aggiorna.

Assicurarsi che venga visualizzato il file di output nella cartella fromonprem del contenitore adftutorial.
Selezionare la scheda Autore a sinistra per passare alla modalità di modifica. Usando l'editor è possibile aggiornare i servizi collegati, i set di dati e le pipeline creati dallo strumento. Selezionare Codice per visualizzare il codice JSON associato all'entità aperta nell'editor. Per informazioni dettagliate su come modificare queste entità nell'interfaccia utente di Data Factory, vedere la versione del portale Azure di questa esercitazione.

Contenuto correlato
La pipeline in questo esempio copia i dati da un database SQL Server nell'archivio BLOB. Hai imparato come:
- Creare una fabbrica di dati.
- Usare lo strumento Copia dati per creare una pipeline.
- Monitora le esecuzioni delle pipeline e delle attività.
Per un elenco degli archivi dati supportati da Data Factory, vedere la tabella degli archivi dati supportati.
Per informazioni sulla copia di dati in blocco da un'origine a una destinazione, passare all'esercitazione successiva: