Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
Usare le strategie seguenti per ottimizzare le prestazioni delle trasformazioni nei flussi di dati di mapping nelle pipeline di Azure Data Factory e Azure Synapse Analytics.
Ottimizzazione di operazioni Join, Exist e Lookup
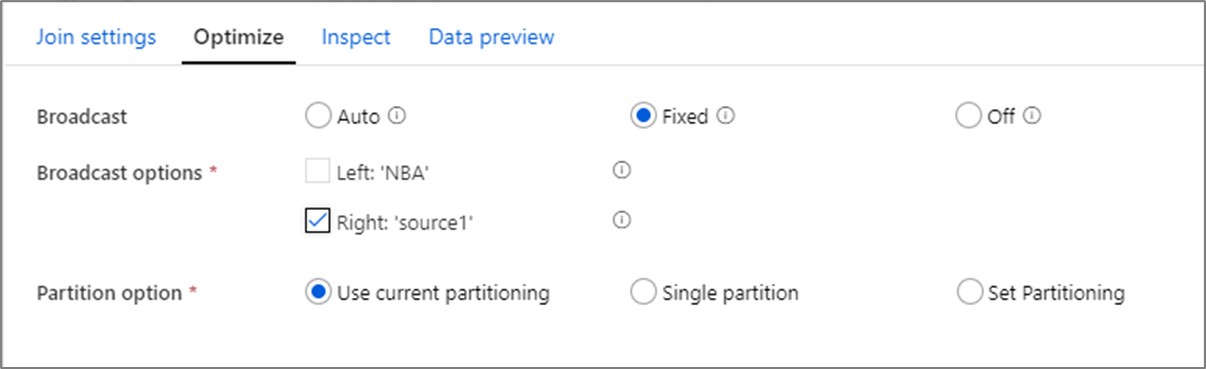
Trasmissione
Nei join, nelle ricerche e nelle trasformazioni exists, se uno o entrambi i flussi di dati sono sufficientemente piccoli da entrare nella memoria del nodo di lavoro, è possibile ottimizzare le prestazioni abilitando Broadcasting. La trasmissione è quando si inviano frame di dati di piccole dimensioni a tutti i nodi del cluster. In questo modo il motore Spark può eseguire un join senza rimescolare i dati nel flusso di dati di grandi dimensioni. Per impostazione predefinita, il motore Spark decide automaticamente se trasmettere o meno un lato di un join. Se si ha familiarità con i dati in ingresso e si sa che un flusso è più piccolo dell'altro, è possibile selezionare Trasmissione fissa . La trasmissione fissa impone a Spark di trasmettere il flusso selezionato.
Se le dimensioni dei dati trasmessi sono troppo grandi per il nodo Spark, è possibile che venga visualizzato un errore di memoria insufficiente. Per evitare errori di memoria insufficiente, usare cluster ottimizzati per la memoria . Se si verificano timeout di trasmissione durante le esecuzioni del flusso di dati, è possibile disattivare l'ottimizzazione della trasmissione. Ciò comporta tuttavia un rallentamento delle prestazioni dei flussi di dati.
Quando si usano origini dati che possono richiedere più tempo per eseguire query, ad esempio query di database di grandi dimensioni, è consigliabile disattivare la trasmissione per i join. L'origine con tempi di query lunghi può causare il timeout di Spark quando il cluster tenta di trasmettere ai nodi di calcolo. Un'altra scelta ottimale per disattivare la trasmissione è quando si dispone di un flusso nel flusso di dati che aggrega i valori da usare in una trasformazione di ricerca in un secondo momento. Questo modello può confondere l'ottimizzatore di Spark e causare il timeout.
Cross join
Se nelle condizioni di join si usano valori letterali o se si hanno più corrispondenze su entrambi i lati di un join, Spark esegue il join come cross join. Un cross join è un prodotto cartesiano completo che filtra quindi i valori uniti. Questo è più lento rispetto ad altri tipi di join. Assicurarsi di disporre di riferimenti a colonne su entrambi i lati delle condizioni di join per evitare l'impatto sulle prestazioni.
Ordinamento prima dei join
A differenza di Merge join in strumenti come SSIS, la trasformazione tramite join non rappresenta un'operazione di merge obbligatoria. Le chiavi di join non richiedono l'ordinamento prima della trasformazione. L'uso delle trasformazioni di Ordinamento nei flussi di dati di mapping non è consigliato.
Prestazioni della trasformazione finestra
La Window transformation Finestra nel flusso di dati per mapping suddivide i dati in base ai valori delle colonne che si selezionano come parte della clausola over() nelle impostazioni di trasformazione. Nella trasformazione Windows sono esposte molte funzioni di aggregazione e analitiche comuni. Tuttavia, se il caso d'uso consiste nel generare una finestra sull'intero set di dati per la classificazione rank() o il numero rowNumber()di riga, è consigliabile usare invece la trasformazione Classificazione e la trasformazione Chiave surrogata. Queste trasformazioni offrono prestazioni migliori per le operazioni complete del set di dati usando tali funzioni.
Ripartizione dei dati asimmetrici
Alcune trasformazioni, ad esempio join e aggregazioni, ricompilano le partizioni di dati e possono talvolta causare dati asimmetrici. I dati asimmetrici indicano che i dati non vengono distribuiti uniformemente tra le partizioni. I dati molto asimmetrici possono comportare trasformazioni downstream e scritture in un sink più lente. È possibile controllare l'asimmetria dei dati in qualsiasi punto di un flusso di dati eseguito facendo clic sulla trasformazione nella visualizzazione del monitoraggio.

Il monitoraggio mostra come i dati vengono distribuiti in ogni partizione, insieme a due metriche, ovvero indice di asimmetria e curtosi. L'asimmetria è una misura del modo in cui i dati asimmetrici sono e possono avere un valore positivo, zero, negativo o non definito. L'asimmetria negativa indica che la coda sinistra è più lunga rispetto a destra. La curtosi è la misura che indica se i dati sono a coda pesante oppure a coda leggera. Elevati valori di curtosi non sono desiderabili. Gli intervalli ideali di asimmetria sono compresi tra -3 e 3, mentre i valori ideali di curtosi sono inferiori a 10. Un modo semplice per interpretare questi numeri è esaminare il grafico delle partizioni e vedere se 1 barra è maggiore del resto.
Se i dati non vengono partizionati uniformemente dopo una trasformazione, è possibile usare la scheda Ottimizza per ripartizionare. La ricombinazione dei dati richiede tempo e potrebbe non migliorare le prestazioni del flusso di dati.
Suggerimento
Se si ripartizionano i dati, ma si hanno trasformazioni downstream che ricalcolano i dati, usare il partizionamento hash su una colonna usata come chiave di join.
Annotazioni
Le trasformazioni nel flusso di dati (ad eccezione della trasformazione Sink) non modificano il partizionamento di file e cartelle dei dati archiviati. Il partizionamento in ogni trasformazione ripartisce i dati all'interno dei frame di dati del cluster Spark serverless temporaneo gestito da Azure Data Factory per ogni esecuzione del flusso di dati.
Contenuti correlati
- Panoramica delle prestazioni del flusso di dati
- Ottimizzazione delle fonti
- Ottimizzazione dei sink
- Uso dei flussi di dati nelle pipeline
Vedere altri articoli sul flusso di dati relativi alle prestazioni: