Azure Data Lake Storage
An Azure service that provides an enterprise-wide hyper-scale repository for big data analytic workloads and is integrated with Azure Blob Storage.
This browser is no longer supported.
Upgrade to Microsoft Edge to take advantage of the latest features, security updates, and technical support.
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3ERO%3C/text%3E%3C/svg%3E)
Hey there,
I am having an issue querying the data from the Synapse Link for Dataverse in a Spark Notebook within Synapse.
I am able to run a SQL query against the data (which appears in Synapse as a Lake Database) and it returns data. See below
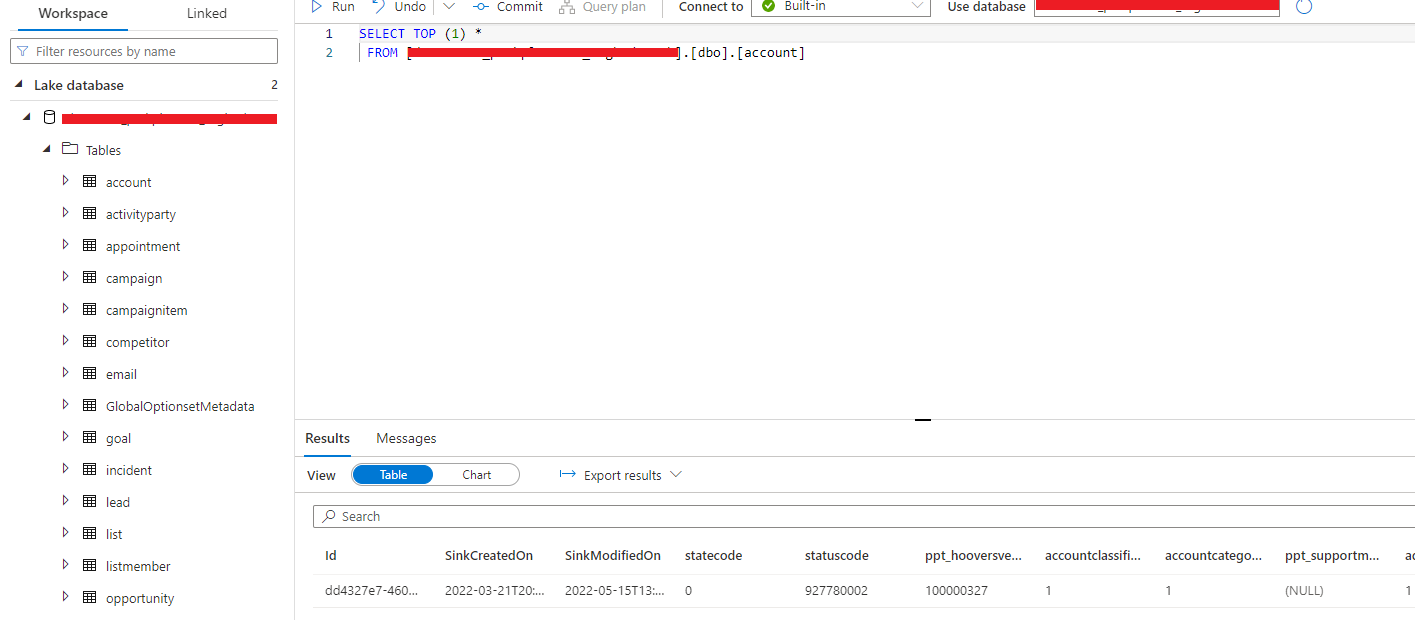
However when I run a query in Spark Notebook I get the following error:
AnalysisException: org.apache.hadoop.hive.ql.metadata.HiveException: java.lang.NullPointerException
Traceback (most recent call last):
File "/opt/spark/python/lib/pyspark.zip/pyspark/sql/session.py", line 723, in sql
return DataFrame(self._jsparkSession.sql(sqlQuery), self._wrapped)
File "/home/trusted-service-user/cluster-env/env/lib/python3.8/site-packages/py4j/java_gateway.py", line 1304, in call
return_value = get_return_value(
File "/opt/spark/python/lib/pyspark.zip/pyspark/sql/utils.py", line 117, in deco
raise converted from None
pyspark.sql.utils.AnalysisException: org.apache.hadoop.hive.ql.metadata.HiveException: java.lang.NullPointerException
See Screenshot~:
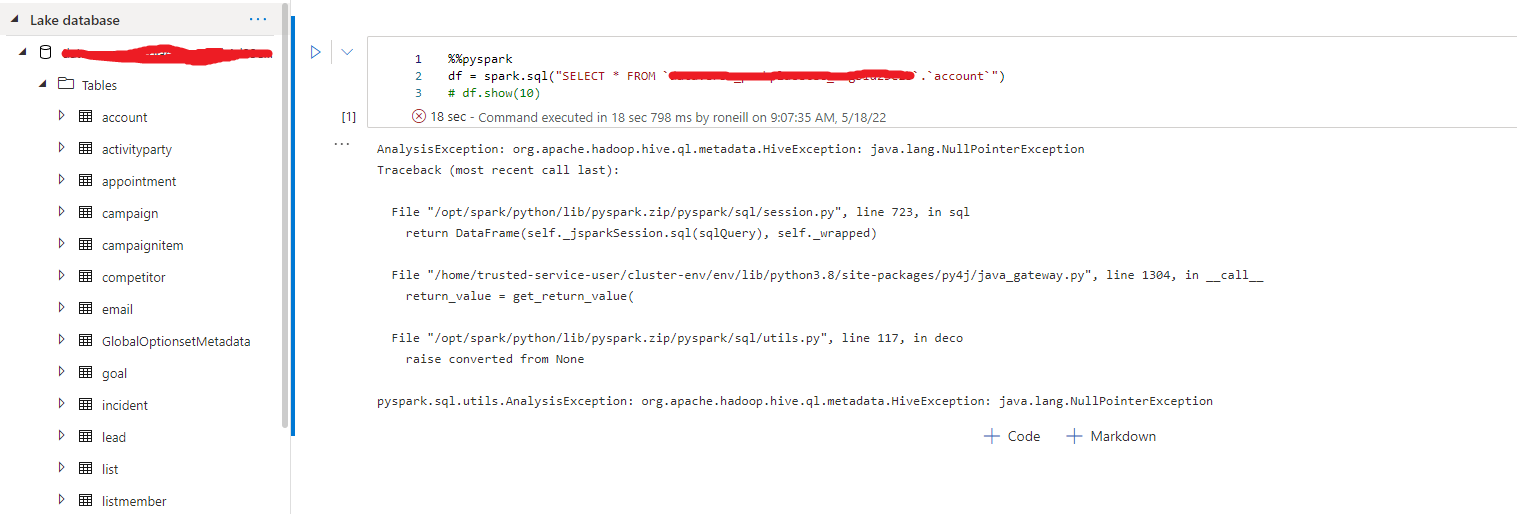
The Synapse workspace has Owner and Storage Blob Data Contributor access on the storage account.
Anyone have any ideas? I'm really stuck with this one.
An Azure service that provides an enterprise-wide hyper-scale repository for big data analytic workloads and is integrated with Azure Blob Storage.
An Azure analytics service that brings together data integration, enterprise data warehousing, and big data analytics. Previously known as Azure SQL Data Warehouse.
.NET: Microsoft Technologies based on the .NET software framework. Machine learning: A type of artificial intelligence focused on enabling computers to use observed data to evolve new behaviors that have not been explicitly programmed.
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3EH%3C/text%3E%3C/svg%3E)
Hello @Robert O'Neill ,
Thanks for the question and using MS Q&A platform.
As we understand the ask here is how to get around the error while running the notebook scripts ., please do let us know if its not accurate.
Try adding yourself to “Storage Blob Data Contributor”.. as the session run on your context you should have access to the underlaying storage..
Please do let me if you have any queries.
Thanks
Himanshu
 or upvote
or upvote  button whenever the information provided helps you. Original posters help the community find answers faster by identifying the correct answer. Here is how
button whenever the information provided helps you. Original posters help the community find answers faster by identifying the correct answer. Here is how
Thanks for the reply Himanshu.
That's correct I am trying to query the data in Spark Notebook.
I already have Storage Blob Data Contributor access.
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3EBD%3C/text%3E%3C/svg%3E)
Did you ever solve this? Having this exact same issue in 2025 still