Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
Von Bedeutung
Lakebase Autoscaling ist die neueste Version von Lakebase mit automatischer Berechnung, Skalierung bis Null, Verzweigung und sofortiger Wiederherstellung. Unterstützte Regionen finden Sie unter "Verfügbarkeit der Region". Wenn Sie ein Lakebase Provisioned-Benutzer sind, lesen Sie Lakebase Provisioned.
Am Ende dieses Leitfadens haben Sie eine laufende Postgres-Datenbank mit Beispieldaten, die mit unity Catalog verbunden sind, mit Daten, die zwischen Lakebase und dem Databricks Lakehouse fließen.
Schritte: (1) Erstellen eines Projekts → (2) Verbinden → (3) Erstellen einer Tabelle → (4) Registrieren im Unity-Katalog → (5) Serve-Daten
Schritt 1: Erstellen Ihres ersten Projekts
Öffnen Sie die Lakebase-App über den App-Switcher.

Wählen Sie "Automatische Skalierung" aus, um auf die Lakebase-Benutzeroberfläche für die automatische Skalierung zuzugreifen.
Klicke auf Neues Projekt. Geben Sie Ihrem Projekt einen Namen, und wählen Sie Ihre Postgres-Version aus. Ihr Projekt wird mit einem einzelnen production Branch, einer Standard databricks_postgres Datenbank und konfigurierten Computerressourcen für den Branch erstellt.

Es kann einige Minuten dauern, bis Die Berechnung aktiviert wird. Die Berechnung für die production Verzweigung ist standardmäßig aktiviert (Scale-to-Zero ist deaktiviert), Sie können diese Einstellung jedoch bei Bedarf konfigurieren.
Die Region für Ihr Projekt wird automatisch auf Ihre Arbeitsbereichsregion festgelegt.
Weitere Informationen: Erstellen eines Projekts | für die automatische Skalierung | auf Null
Schritt 2: Herstellen einer Verbindung mit Ihrer Datenbank
Wählen Sie im Projekt den Produktionszweig aus, und klicken Sie auf "Verbinden". Verbindungszeichenfolgen funktionieren mit jedem Standard-Postgres-Client (psql, pgAdmin, DBeaver oder Anwendungsframework).

Um eine Verbindung mit Ihrer Databricks-Identität herzustellen, kopieren Sie den psql Codeausschnitt aus dem Verbindungsdialogfeld, und fügen Sie das OAuth-Token ein, wenn Sie dazu aufgefordert werden:
psql 'postgresql://your-email@databricks.com@ep-abc-123.databricks.com/databricks_postgres?sslmode=require'
Weitere Informationen: Verbindungsschnellstart | psql | pgAdmin | Postgres-Clients
Schritt 3: Erstellen der ersten Tabelle
Der Lakebase SQL-Editor ist bereits mit SQL-Beispielen geladen. Wählen Sie in Ihrem Projekt den Produktionszweig aus, öffnen Sie den SQL-Editor, und führen Sie die bereitgestellten Anweisungen aus, um eine playing_with_lakebase Tabelle zu erstellen und Beispieldaten einzufügen.
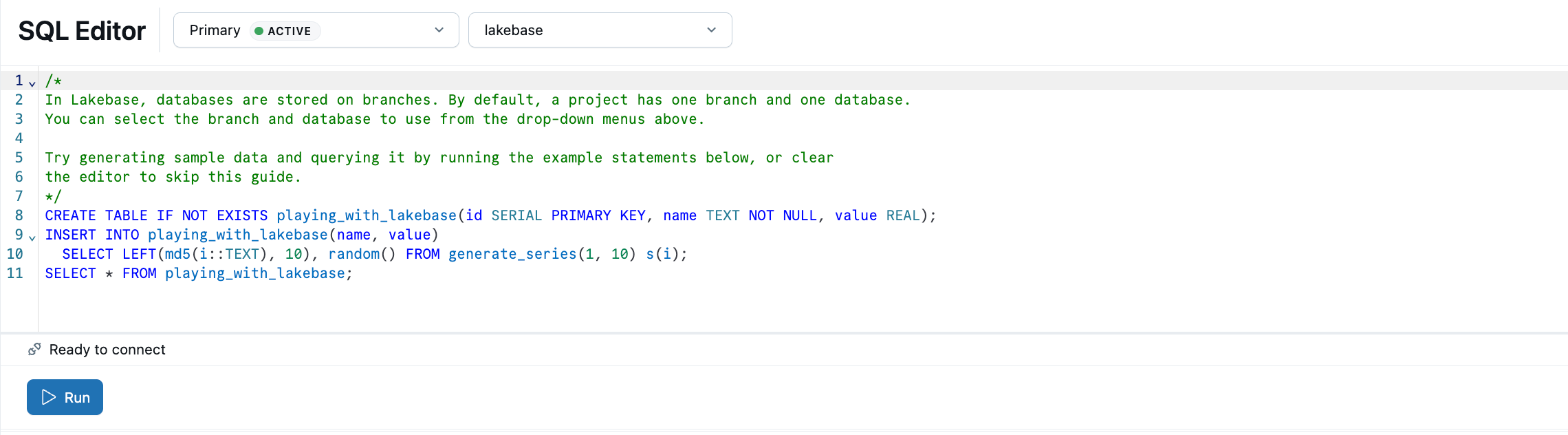
Weitere Informationen: SQL Editor | Tables Editor | Postgres-Clients
Schritt 4: Registrieren im Unity-Katalog
Ihre Lakebase-Datenbank wird ausgeführt, aber sie ist für den Rest der Databricks-Plattform unsichtbar, bis Sie sie im Unity Catalog registrieren. Nach der Registrierung können Sie Lakebase-Tabellen aus Databricks SQL abfragen, operative Daten mit Lakehouse-Analysen verknüpfen und einheitliche Governance anwenden.
Erstellen Sie im Katalog-Explorer einen neuen Katalog mit Lakebase Autoscaling als Typ, der auf den production Zweig und die databricks_postgres Datenbank Ihres Projekts verweist.

Sie können jetzt aus einem SQL-Lagerhaus abfragen:
SELECT * FROM lakebase_catalog.public.playing_with_lakebase;
Weitere Informationen: Registrieren im Unity-Katalog
Schritt 5: Bereitstellen von Lakehouse-Daten in Ihrer App
Synchronisierte Tabellen bringen analytische Daten aus dem Unity-Katalog in Ihre Lakebase-Datenbank, damit Anwendungen sie mit Transaktionslesevorgängen mit geringer Latenz abfragen können. Erstellen Sie eine Beispiel-Unity-Katalogtabelle, und synchronisieren Sie sie dann mit Lakebase.
Erstellen Sie in einem SQL Warehouse oder Notizbuch eine Quelltabelle:
CREATE TABLE main.default.user_segments AS
SELECT * FROM VALUES
(1001, 'premium', 2500.00, 'high'),
(1002, 'standard', 450.00, 'medium'),
(1003, 'premium', 3200.00, 'high'),
(1004, 'basic', 120.00, 'low')
AS segments(user_id, tier, lifetime_value, engagement);
Synchronisieren Sie diese Tabelle nun mit Lakebase. Erstellen Sie im Katalog-Explorer eine synchronisierte Tabelle aus user_segments dem Snapshot-Modus , die auf die databricks_postgres Datenbank Ihres Projekts ausgerichtet ist. Der Momentaufnahmemodus kopiert die Daten einmal. Verwenden Sie für fortlaufende Updates den ausgelösten oder fortlaufenden Modus.
Sobald die Synchronisierung abgeschlossen ist, sind die Daten in Lakebase als default.user_segments_synced verfügbar. Fragen Sie sie im SQL-Editor der Lakebase ab:
SELECT * FROM "default".user_segments_synced WHERE engagement = 'high';
Hinweis
default muss zitiert werden, da es sich um ein reserviertes Schlüsselwort von PostgreSQL handelt. Das schema der synchronisierten Tabelle erbt den Namen des Unity-Katalogschemas. Wenn Ihr Schema also benannt defaultist, müssen Sie es immer in Abfragen zitieren. Anführungszeichen um andere Bezeichner sind optional.

Ihre Lakehouse-Analyse kann jetzt aus Ihrer Transaktionsdatenbank bedient werden.
Weitere Informationen: Synchronisierte Tabellen | Synchronisierungsmodi | Datentypzuordnung
Nächste Schritte
- Erstellen einer App:Databricks Apps Lernprogramm | für externe Apps
- Entwickeln mit Branches:Branch-based development tutorial
- Richten Sie Ihr Team ein:Gewähren Sie Projekt- und Datenbankzugriff
- Erkunden Sie die Plattform:Kernkonzepte | Projekte Übersicht | Alle Lernprogramme