Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
Hinweis
Dieser Artikel behandelt Databricks Connect für Databricks Runtime Version 13.3 LTS und höher.
Databricks Connect ist eine Clientbibliothek für die Databricks-Runtime, mit der Sie eine Verbindung mit Azure Databricks herstellen können, die von IDEs wie Visual Studio Code, PyCharm und IntelliJ IDEA, Notizbüchern und jeder benutzerdefinierten Anwendung berechnet werden, um neue interaktive Benutzeroberflächen basierend auf Ihrem Azure Databricks Lakehouse zu ermöglichen.
Databricks Connect ist für die folgenden Sprachen verfügbar:
Was kann ich mit Databricks Connect tun?
Mithilfe von Databricks Connect können Sie Code mit Spark-APIs schreiben und remote auf Azure Databricks computen statt in der lokalen Spark-Sitzung ausführen.
Interaktiv entwickeln und debuggen Sie aus jeder IDE. Databricks Connect ermöglicht Es Entwicklern, ihren Code auf Databricks zu entwickeln und zu debuggen, indem sie die systemeigene Ausführungs- und Debuggingfunktionalität einer beliebigen IDE verwenden. Die Databricks Visual Studio Code-Erweiterung verwendet Databricks Connect, um integriertes Debuggen von Benutzercode auf Databricks bereitzustellen.
Erstellen Sie interaktive Daten-Apps. Genau wie ein JDBC-Treiber kann die Databricks Connect-Bibliothek in jede Anwendung eingebettet werden, um mit Databricks zu interagieren. Databricks Connect bietet die volle Ausdrucksfähigkeit von Python über PySpark, wodurch die Impedanzfehlanpassung der SQL-Programmiersprache eliminiert wird und Sie alle Datentransformationen mit Spark auf serverlosen, skalierbaren Rechnerkapazitäten von Databricks ausführen können.
Wie funktioniert es?
Databricks Connect basiert auf Open-Source Spark Connect, das über eine entkoppelte Clientserverarchitektur für Apache Spark verfügt, die die Remotekonnektivität mit Spark-Clustern mithilfe der DataFrame-API ermöglicht. Das zugrunde liegende Protokoll verwendet Spark unresolved logical plans und Apache Arrow auf gRPC. Die Client-API ist so konzipiert, dass sie schlank und überall problemlos eingebettet werden kann: in Anwendungsservern, IDEs, Notebooks und Programmiersprachen.
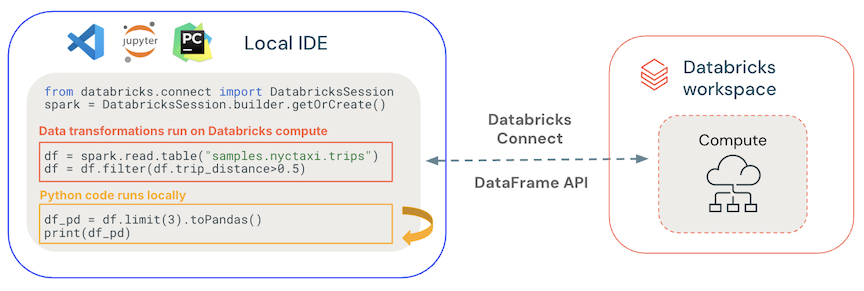
- Allgemeiner Code wird lokal ausgeführt: Python- und Scala-Code wird auf der Clientseite ausgeführt und ermöglicht das interaktive Debuggen. Der gesamte Code wird lokal ausgeführt, während der gesamte Spark-Code weiterhin auf dem Remotecluster ausgeführt wird.
-
DataFrame-APIs werden auf databricks compute ausgeführt. Alle Datentransformationen werden in Spark-Pläne konvertiert und auf der Databricks-Compute-Einheit über die Remote-Spark-Sitzung ausgeführt. Sie werden auf Ihrem lokalen Client materialisiert, wenn Sie Befehle wie
collect(),show()undtoPandas()verwenden. -
UDF-Code wird auf Databricks compute ausgeführt: UDFs, die lokal definiert wurden, werden serialisiert und an den Cluster übertragen, in dem er ausgeführt wird. APIs, die Benutzercode für Databricks ausführen, umfassen: UDFs,
foreach, ,foreachBatchundtransformWithState. - Für Abhängigkeitsverwaltung:
- Installieren Sie Anwendungsabhängigkeiten auf Ihrem lokalen Computer. Diese werden lokal ausgeführt und müssen als Teil Ihres Projekts installiert werden, z. B. Teil Ihrer virtuellen Python-Umgebung.
- Installieren Sie UDF-Abhängigkeiten von Databricks. Siehe Verwalten von UDF-Abhängigkeiten.
Wie sind Databricks Connect und Spark Connect verwandt?
Spark Connect ist ein open-source gRPC-basiertes Protokoll in Apache Spark, das die Remoteausführung von Spark-Workloads mithilfe der DataFrame-API ermöglicht.
Für Databricks Runtime 13.3 LTS und höher ist Databricks Connect eine Erweiterung von Spark Connect mit Ergänzungen und Änderungen zur Unterstützung der Arbeit mit Databricks-Berechnungsmodi und Unity Catalog.
Nächste Schritte
In den folgenden Lernprogrammen können Sie schnell mit der Entwicklung von Databricks Connect-Lösungen beginnen:
- Databricks Connect für Python Classic Compute Tutorial
- Databricks Connect für Python serverloses Compute-Lernprogramm
- Databricks Connect für ein klassisches Scala Compute Tutorial
- Databricks Connect für Scala serverloses Compute-Lernprogramm
- Databricks Connect für R-Lernprogramm
Beispielanwendungen, die Databricks Connect verwenden, finden Sie im GitHub-Beispiel-Repository, das die folgenden Beispiele enthält: