Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
Gilt für: Azure Data Factory
Azure Data Factory  Azure Synapse Analytics
Azure Synapse Analytics
Tipp
Data Factory in Microsoft Fabric ist die nächste Generation von Azure Data Factory mit einer einfacheren Architektur, integrierter KI und neuen Features. Wenn Sie mit der Datenintegration noch nicht vertraut sind, beginnen Sie mit Fabric Data Factory. Vorhandene ADF-Workloads können auf Fabric aktualisiert werden, um auf neue Funktionen in der Datenwissenschaft, Echtzeitanalysen und Berichterstellung zuzugreifen.
Wenn Sie neu bei Azure Data Factory sind, lesen Sie Einführung in Azure Data Factory.
In diesem Lernprogramm verwenden Sie die Data Factory-Benutzeroberfläche (UI), um eine Pipeline zu erstellen, die Daten von einer Azure Data Lake Storage Gen2-Quelle zu einer Data Lake Storage Gen2-Senke kopiert und transformiert (beide erlauben nur den Zugriff auf ausgewählte Netzwerke) mithilfe von Mapping Data Flow im Data Factory verwalteten virtuellen Netzwerk. Sie können das Konfigurationsmuster in diesem Tutorial erweitern, wenn Sie Daten mithilfe des Zuordnungsdatenflusses transformieren.
In diesem Tutorial führen Sie die folgenden Schritte aus:
- Erstellen einer Data Factory
- Erstellen einer Pipeline mit einer Datenflussaktivität
- Erstellen Sie einen Mapping-Datenfluss mit vier Transformationen.
- Ausführen eines Testlaufs für die Pipeline
- Überwachen einer Datenflussaktivität
Voraussetzungen
- Azure-Abonnement. Wenn Sie kein Azure-Abonnement haben, erstellen Sie ein free Azure Konto, bevor Sie beginnen.
- Azure Speicherkonto. Sie verwenden Data Lake Storage als source und sink Datenspeicher. Wenn Sie nicht über ein Speicherkonto verfügen, lesen Sie Erstellen eines Azure-Speicherkontos, um die Schritte zur Erstellung eines solchen Kontos zu erfahren. Stellen Sie sicher, dass das Speicherkonto nur den Zugriff aus ausgewählten Netzwerken zulässt.
Die Datei, die wir in diesem Lernprogramm transformieren, ist moviesDB.csv, die auf dieser GitHub-Inhaltswebsite zu finden ist. Um die Datei aus GitHub abzurufen, kopieren Sie den Inhalt in einen Text-Editor Ihrer Wahl, um sie lokal als .csv Datei zu speichern. Informationen zum Hochladen der Datei in Ihr Speicherkonto finden Sie unter Upload-Blobs mit dem Azure Portal. In den Beispielen wird auf einen Container mit dem Namen sample-data verwiesen.
Erstellen einer Data Factory
In diesem Schritt erstellen Sie eine Data Factory und öffnen die Data Factory-Benutzeroberfläche, um eine Pipeline in der Data Factory zu erstellen.
Öffnen Sie Microsoft Edge oder Google Chrome. Derzeit unterstützen nur Microsoft Edge und Google Chrome-Webbrowser die Data Factory UI.
Klicken Sie im Menü auf der linken Seite auf Ressource erstellen>Analytics>Data Factory.
Geben Sie auf der Seite Neue Data Factory unter Name den Namen ADFTutorialDataFactory ein.
Der Name der Data Factory muss global eindeutig sein. Wenn eine Fehlermeldung zum Namenswert angezeigt wird, geben Sie einen anderen Namen für die Data Factory ein (z. B. IhrNameADFTutorialDataFactory). Benennungsregeln für Data Factory-Artefakte finden Sie im Thema Azure Data Factory – Benennungsregeln.
Wählen Sie das Azure Abonnement aus, in dem Sie die Data Factory erstellen möchten.
Führen Sie unter Ressourcengruppe einen der folgenden Schritte aus:
- Wählen Sie Use existing und dann eine vorhandene Ressourcengruppe aus der Dropdownliste aus.
- Wählen Sie Neu erstellen, und geben Sie den Namen einer Ressourcengruppe ein.
Weitere Informationen zu Ressourcengruppen finden Sie unter Ressourcengruppen zum Verwalten Ihrer Azure Ressourcen.
Wählen Sie unter Version die Option V2.
Wählen Sie unter Standort einen Standort für die Data Factory aus. In der Dropdownliste werden nur unterstützte Standorte angezeigt. Datenspeicher (z. B. Azure Storage und Azure SQL-Datenbank) und Berechnungen (z. B. Azure HDInsight), die von der Datenfactory verwendet werden, können in anderen Regionen vorhanden sein.
Klicken Sie auf Erstellen.
Nach Abschluss der Erstellung wird der Hinweis im Benachrichtigungscenter angezeigt. Wählen Sie Zu Ressource wechseln aus, um zur Seite Data Factory zu navigieren.
Wählen Sie Open Azure Data Factory Studio aus, um die Datenfactory-Benutzeroberfläche auf einer separaten Registerkarte zu starten.
Erstellen einer Azure IR im von der Data Factory verwalteten virtuellen Netzwerk
In diesem Schritt erstellen Sie eine Azure IR und aktivieren das von Data Factory verwaltete virtuelle Netzwerk.
Wechseln Sie im Data Factory-Portal zu Manage, und wählen Sie Neu aus, um eine neue Azure IR zu erstellen.
Screenshot, der das Erstellen einer neuen Azure IR zeigt. Wählen Sie auf der Seite Integration Runtime-Setup basierend auf den erforderlichen Funktionen die Integration Runtime aus, die erstellt werden soll. Wählen Sie in diesem Lernprogramm Azure, Self-Hosted aus, und klicken Sie dann auf Continue.
Wählen Sie Azure aus, und klicken Sie dann auf Continue, um eine Azure Integrationslaufzeit zu erstellen.

Wählen Sie unter Konfiguration des virtuellen Netzwerks (Vorschau) die Option Aktivieren aus.

Klicken Sie auf Erstellen.
Erstellen einer Pipeline mit einer Datenflussaktivität
In diesem Schritt erstellen Sie eine Pipeline mit einer Datenflussaktivität.
Wählen Sie auf der Startseite von Azure Data Factory Orchestrate aus.
Geben Sie im Bereich „Eigenschaften“ der Pipeline als Pipeline-Namen TransformMovies ein.
Erweitern Sie im Bereich Aktivitäten die Option Verschieben und Transformieren. Ziehen Sie die Aktivität Datenfluss per Drag & Drop aus dem Bereich auf die Canvas der Pipeline.
Wählen Sie im Pop-up-Fenster Datenfluss hinzufügen, Neuen Datenfluss erstellen und dann Mapping Datenfluss aus. Wählen Sie OK aus, wenn Sie fertig sind.
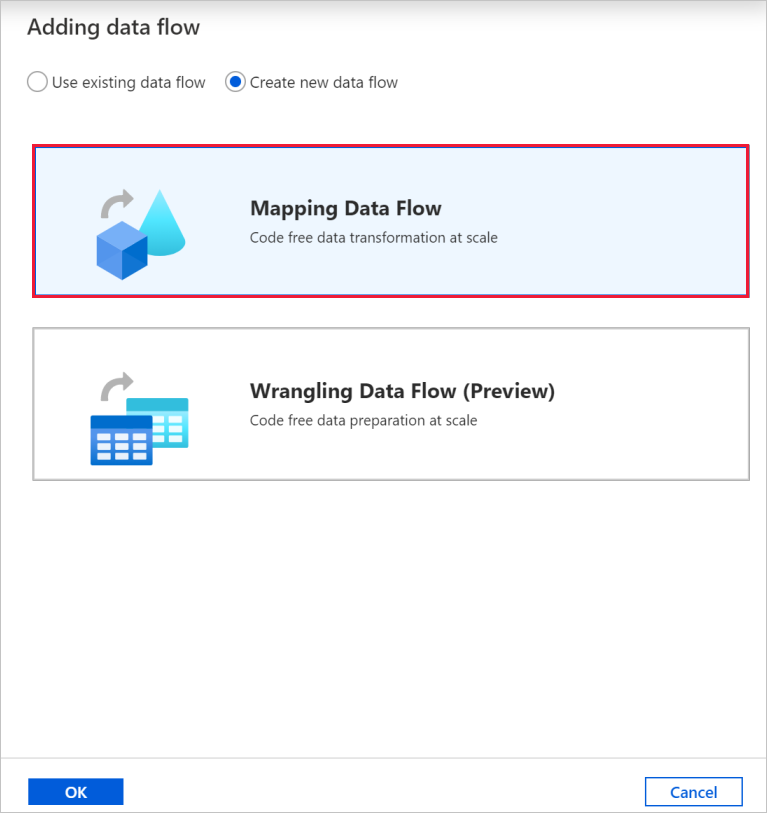
Geben Sie Ihrem Datenfluss im Bereich „Eigenschaften“ den Namen TransformMovies.
Setzen Sie den Schieberegler Datenfluss debuggen in der oberen Pipeline-Canvas-Leiste auf „ein“. Der Debugmodus ermöglicht das interaktive Testen von Transformationslogik mit einem aktiven Spark-Cluster. Datenfluss-Cluster benötigen 5 bis 7 Minuten zum Aufwärmen, und es wird empfohlen, dass die Benutzer zuerst das Debuggen aktivieren, wenn sie eine Datenfluss-Entwicklung durchführen möchten. Weitere Informationen finden Sie unter Debugmodus.

Erstellen von Transformationslogik im Datenfluss-Arbeitsbereich
Nachdem Sie den Datenfluss erstellt haben, werden Sie automatisch zur Datenflusscanvas geleitet. In diesem Schritt erstellen Sie einen Datenfluss, der die Datei moviesDB.csv aus dem Data Lake Storage verwendet und die durchschnittliche Bewertung von Komödien von 1910 bis 2000 aggregiert. Anschließend schreiben Sie diese Datei wieder in Data Lake Storage.
Hinzufügen der Quelltransformation
In diesem Schritt richten Sie Data Lake Storage Gen2 als Quelle ein.
Fügen Sie auf der Datenflusscanvas eine Quelle hinzu, indem Sie das Feld Quelle hinzufügen auswählen.
Geben Sie der Quelle den Namen MoviesDB. Wählen Sie Neu aus, um ein neues Quelldataset zu erstellen.
Wählen Sie Azure Data Lake Storage Gen2 und dann Continue aus.
Wählen Sie DelimitedText und dann Weiter aus.
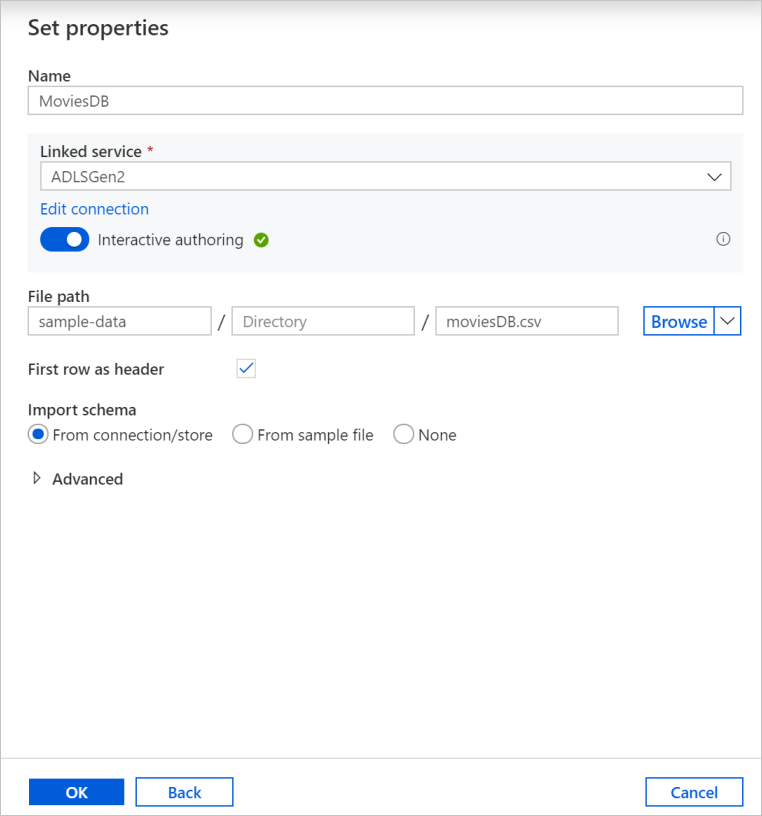
Geben Sie dem Dataset den Namen MoviesDB. Wählen Sie in der Dropdownliste „Verknüpfter Dienst“ Neu aus.
Benennen Sie im Fenster zum Erstellen verknüpfter Dienste Ihren Data Lake Storage Gen2 verknüpften Dienst ADLSGen2 und geben Sie die Authentifizierungsmethode an. Dann geben Sie Ihre Verbindungsanmeldeinformationen ein. In diesem Tutorial wird Kontoschlüssel zum Herstellen einer Verbindung mit dem Speicherkonto verwendet.
Aktivieren Sie unbedingt Interaktive Erstellung. Die Aktivierung kann ungefähr 1 Minute dauern.
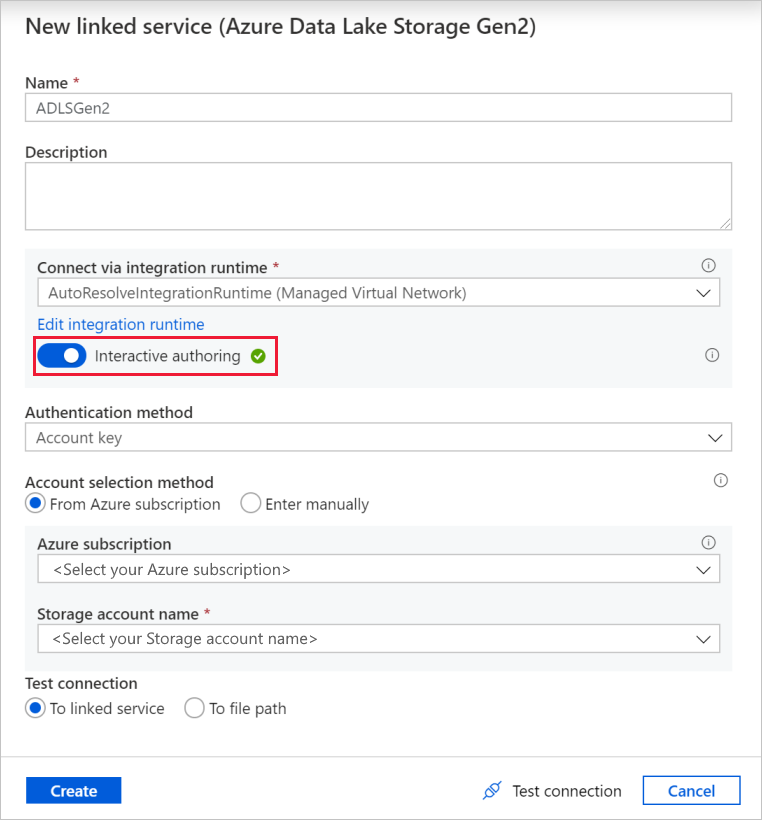
Klicken Sie auf Verbindung testen. Es sollte ein Verbindungsfehler auftreten, weil ohne Erstellung und Genehmigung eines privaten Endpunkts nicht auf das Speicherkonto zugegriffen werden kann. In der Fehlermeldung sollte ein Link zum Erstellen eines privaten Endpunkts angezeigt werden, dem Sie folgen können, um einen verwalteten privaten Endpunkt zu erstellen. Alternativ dazu können Sie direkt zur Registerkarte Verwalten navigieren und die Anweisungen in diesem Abschnitt befolgen, um einen verwalteten privaten Endpunkt zu erstellen.
Lassen Sie das Dialogfeld geöffnet, und navigieren Sie dann zu Ihrem Speicherkonto.
Befolgen Sie die Anweisungen in diesem Abschnitt, um die private Verbindung zu genehmigen.
Gehen Sie zurück zum Dialogfeld. Wählen Sie erneut Verbindung testen und anschließend Erstellen aus, um den verknüpften Dienst bereitzustellen.
Geben Sie auf dem Bildschirm zum Erstellen von Datasets unter dem Feld Dateipfad den Speicherort Ihrer Datei ein. In diesem Tutorial befindet sich die Datei „moviesDB.csv“ im Container sample-data. Da die Datei Kopfzeilen enthält, aktivieren Sie das Kontrollkästchen Erste Zeile als Kopfzeile. Wählen Sie Aus Verbindung/Speicher aus, um das Headerschema direkt aus der Datei im Speicher zu importieren. Wählen Sie OK aus, wenn Sie fertig sind.
Nachdem Ihr Debugcluster gestartet wurde, wechseln Sie zur Registerkarte Datenvorschau der Quelltransformation, und wählen Sie Aktualisieren aus, um eine Momentaufnahme der Daten zu erhalten. Mithilfe der Datenvorschau können Sie überprüfen, ob die Transformation ordnungsgemäß konfiguriert ist.
Erstellen eines verwalteten privaten Endpunkts
Wenn Sie beim Testen der vorhergehenden Verbindung nicht den Link ausgewählt haben, folgen Sie dem Pfad. Jetzt müssen Sie einen verwalteten privaten Endpunkt erstellen, den Sie mit dem erstellten verknüpften Dienst verbinden.
Wechseln Sie zur Registerkarte Verwalten.
Hinweis
Die Registerkarte Verwalten ist möglicherweise nicht für alle Data Factory-Instanzen verfügbar. Wenn Sie diese Option nicht sehen, können Sie auf private Endpunkte zugreifen, indem Sie Autor>Verbindungen>Privater Endpunkt auswählen.
Navigieren Sie zum Abschnitt Verwaltete private Endpunkte.
Wählen Sie unter Verwaltete private Endpunkte die Option + Neu aus.

Wählen Sie die Kachel Azure Data Lake Storage Gen2 aus der Liste aus, und wählen Sie Continue aus.
Geben Sie den Namen des von Ihnen erstellten Speicherkontos ein.
Klicken Sie auf Erstellen.
Nach einigen Sekunden sollten Sie sehen, dass die erstellte Private Link eine Genehmigung benötigt.
Wählen Sie den zuvor erstellten privaten Endpunkt aus. Ein Link wird angezeigt, über den Sie den privaten Endpunkt auf Speicherkontoebene genehmigen können.

Genehmigung eines Private Link in einem Speicherkonto
Navigieren Sie im Speicherkonto im Abschnitt Einstellungen zu Verbindungen mit privatem Endpunkt.
Aktivieren Sie das Kontrollkästchen für den privaten Endpunkt, den Sie oben erstellt haben, und wählen Sie Genehmigen aus.

Fügen Sie eine Beschreibung hinzu, und wählen Sie Ja aus.
Gehen Sie in Data Factory auf der Registerkarte Verwalten zurück zum Abschnitt Verwaltete private Endpunkte.
Nach ca. einer Minute sollten Sie die erteilte Genehmigung für Ihren privaten Endpunkt sehen.
Hinzufügen der Filtertransformation
Wählen Sie auf der Datenflusscanvas neben dem Quellknoten das Pluszeichen aus, um eine neue Transformation hinzuzufügen. Als erste Transformation fügen Sie einen Filter hinzu.

Geben Sie der Filtertransformation den Namen FilterYears. Wählen Sie auf das Ausdrucksfeld neben Filtern nach aus, um den Ausdrucks-Generator zu öffnen. Hier geben Sie dann die Filterbedingung an.

Mit dem Datenfluss-Ausdrucks-Generator können Sie Ausdrücke interaktiv erstellen, die dann in verschiedenen Transformationen verwendet werden können. Ausdrücke können integrierte Funktionen, Spalten aus dem Eingabeschema und benutzerdefinierte Parameter enthalten. Weitere Informationen zum Erstellen von Ausdrücken finden Sie im Data Flow Expression Builder.
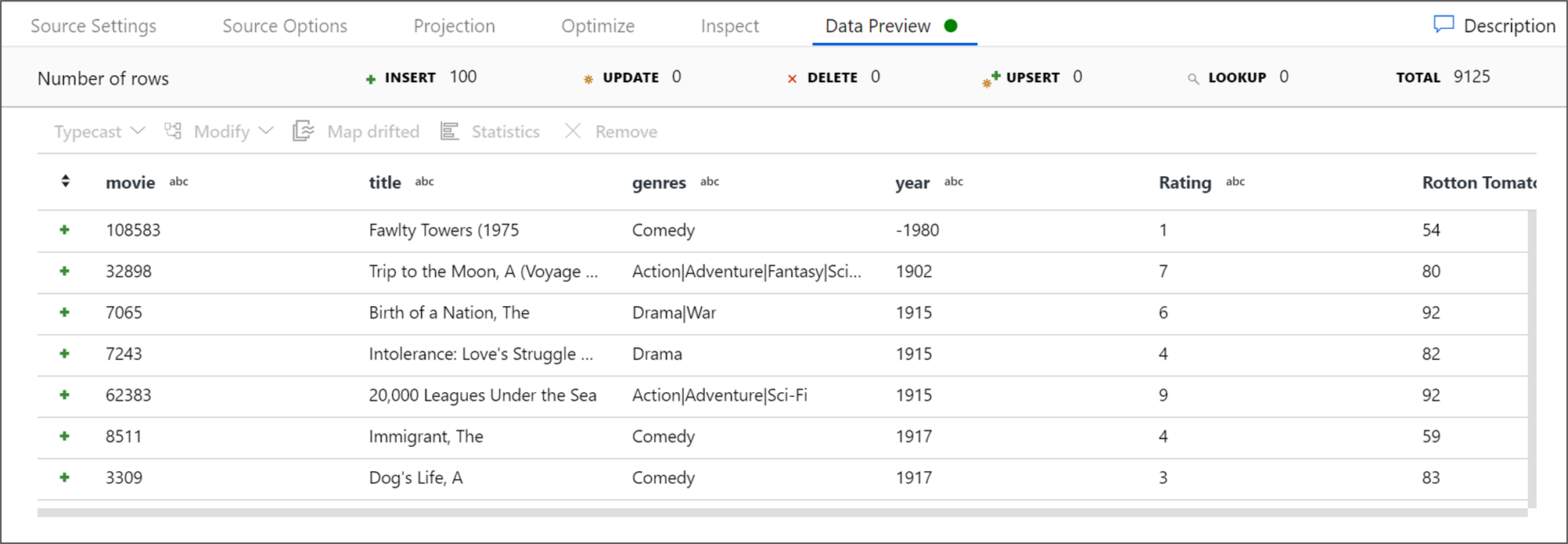
In diesem Tutorial möchten Sie Filme des Genres „Komödie“ filtern, die von 1910 bis 2000 entstanden sind. Da die Jahresangabe derzeit eine Zeichenfolge ist, müssen Sie sie mithilfe der Funktion
toInteger()in eine ganze Zahl konvertieren. Verwenden Sie die Operatoren „Größer oder gleich (>=)“ und „Kleiner oder gleich (<=)“ für einen Vergleich mit den Literalwerten für die Jahre 1910 und 2000. Verbinden Sie diese Ausdrücke mit dem And-Operator (&&). Der Ausdruck sieht wie folgt aus:toInteger(year) >= 1910 && toInteger(year) <= 2000Um zu ermitteln, welche Filme Komödien sind, können Sie mithilfe der Funktion
rlike()in der Spalte „genres“ nach dem Muster „Comedy“ suchen. Verbinden Sie denrlike-Ausdruck mit dem Jahresvergleich, um Folgendes zu erhalten:toInteger(year) >= 1910 && toInteger(year) <= 2000 && rlike(genres, 'Comedy')Wenn ein Debugcluster aktiv ist, können Sie die Logik überprüfen. Wählen Sie dazu Aktualisieren aus, um die Ausdrucksausgabe im Vergleich zu den verwendeten Eingaben anzuzeigen. Es gibt mehrere Möglichkeiten, wie Sie diese Logik mithilfe der Ausdruckssprache für Datenflüsse erzielen können.
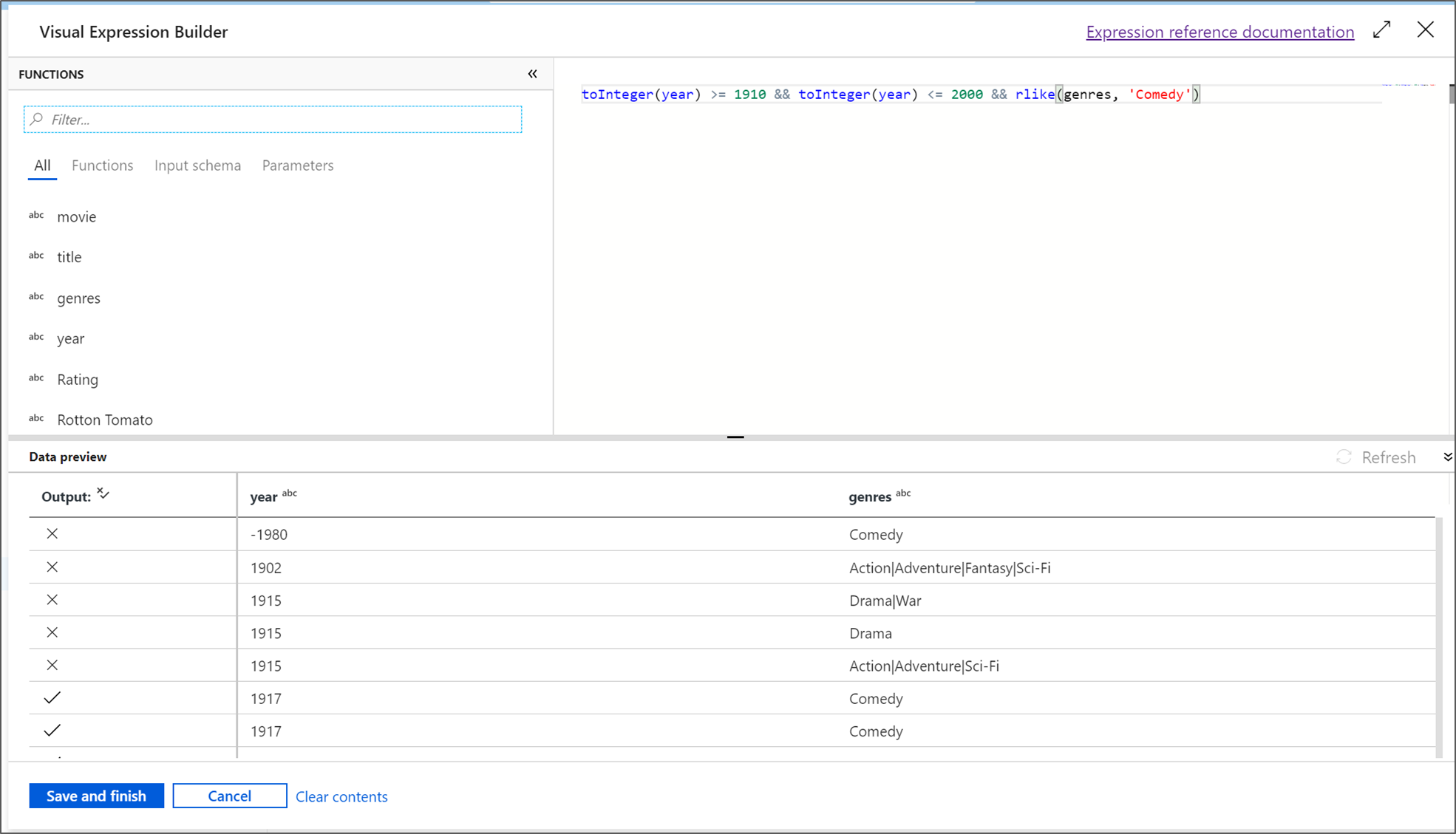
Wählen Sie Speichern und beenden aus, nachdem Sie den Ausdruck fertig gestellt haben.
Rufen Sie eine Datenvorschau ab, um zu überprüfen, ob der Filter ordnungsgemäß funktioniert.
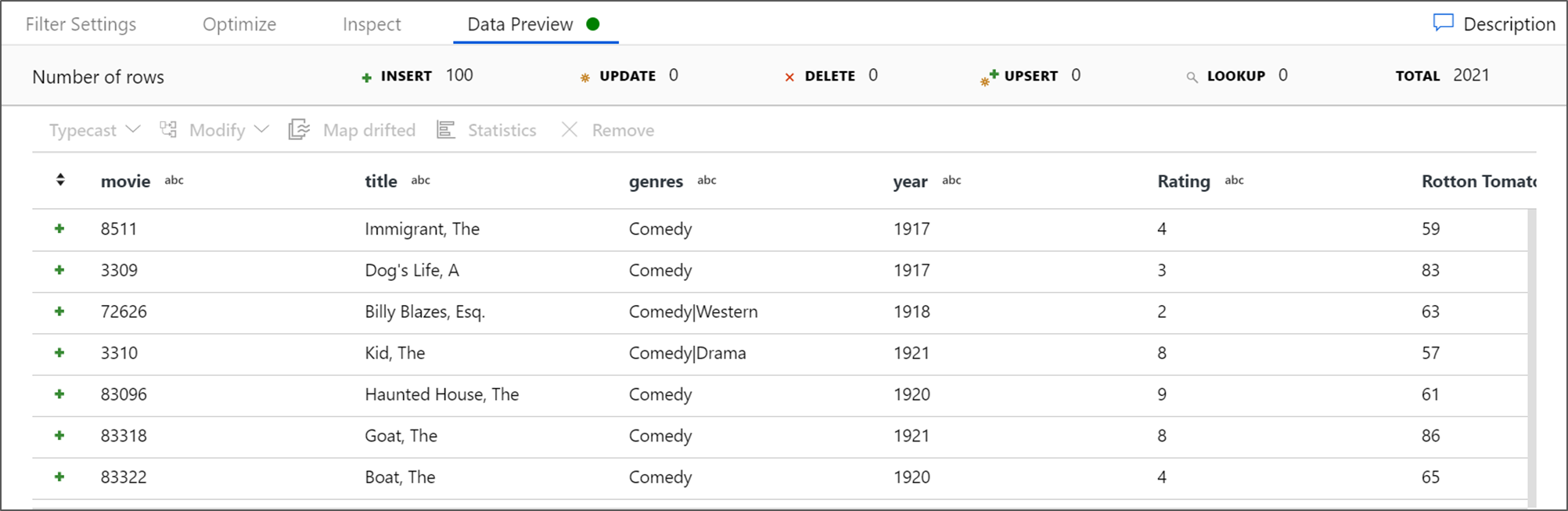
Hinzufügen der Aggregations-Transformation
Als nächste Transformation fügen Sie eine Aggregat-Transformation unter Schemamodifizierer hinzu.

Geben Sie der Aggregattransformation den Namen AggregateComedyRating. Wählen Sie auf der Registerkarte Gruppieren nach in der Dropdownliste year aus, um die Aggregationen nach dem Jahr zu gruppieren, in dem der Film in die Kinos kam.

Wechseln Sie zur Registerkarte Aggregate. Geben Sie im linken Textfeld der Aggregatspalte den Namen AverageComedyRating. Wählen Sie das rechte Ausdrucksfeld aus, um den Aggregatausdruck über den Ausdrucks-Generator einzugeben.

Verwenden Sie die , um den Durchschnitt der Spalte
avg()zu berechnen. Da Rating eine Zeichenfolge ist undavg()eine numerische Eingabe benötigt, muss der Wert über die FunktiontoInteger()in eine Zahl konvertiert werden. Dieser Ausdruck sieht wie folgt aus:avg(toInteger(Rating))Wählen Sie Speichern und beenden aus, wenn Sie fertig sind.

Wechseln Sie zur Registerkarte Datenvorschau, um die Transformationsausgabe anzuzeigen. Es sind nur zwei Spalten vorhanden: year und AverageComedyRating.
Hinzufügen der Senkentransformation
Als Nächstes fügen Sie eine Transformation vom Typ Sink unter Ziel hinzu.

Geben Sie der Senke den Namen Sink. Wählen Sie Neu aus, um das Senkendataset zu erstellen.

Wählen Sie auf der Seite Neues DatasetAzure Data Lake Storage Gen2 und dann Continue aus.
Wählen Sie auf der Seite Format auswählen die Option DelimitedText und dann Weiter aus.
Vergeben Sie dem Zieldataset den Namen MoviesSink. Wählen Sie als verknüpften Dienst denselben verknüpften Dienst ADLSGen2 aus, den Sie für die Quelltransformation erstellt haben. Geben Sie einen Ausgabeordner ein, in den die Daten geschrieben werden sollen. In diesem Tutorial werden Daten in den Ordner output im Container sample-data geschrieben. Der Ordner muss nicht vorab vorhanden sein und kann dynamisch erstellt werden. Aktivieren Sie das Kontrollkästchen Erste Zeile als Kopfzeile, und wählen Sie Kein für Schema importieren aus. Klicken Sie auf OK.

Sie haben nun die Erstellung des Datenflusses beendet. Jetzt können Sie ihn in ihrer Pipeline ausführen.
Führen Sie den Datenfluss aus und überwachen Sie ihn
Sie können eine Pipeline vor der Veröffentlichung debuggen. In diesem Schritt lösen Sie eine Debugausführung der Datenflusspipeline aus. Während bei der Datenvorschau keine Daten geschrieben werden, werden bei einer Debugausführung Daten in das Senkenziel geschrieben.
Wechseln Sie zur Pipelinecanvas. Klicken Sie auf Debuggen, um eine Debugausführung auszulösen.
Für das Debuggen der Pipeline von Datenflussaktivitäten wird der aktive Debugcluster verwendet. Allerdings dauert die Initialisierung mindestens eine Minute. Sie können den Fortschritt über die Registerkarte Ausgabe verfolgen. Wählen Sie nach erfolgreicher Ausführung das Brillensymbol aus, um Ausführungsdetails anzuzeigen.
Auf der Detailseite werden die Anzahl der Zeilen und Dauer der einzelnen Transformationsschritte angezeigt.

Wählen Sie eine Transformation aus, um ausführliche Informationen über die Spalten und Partitionierung der Daten zu erhalten.
Wenn Sie dieses Tutorial richtig durchgeführt haben, sollten 83 Zeilen und 2 Spalten in den Senkenordner geschrieben worden sein. Sie können sich von der Richtigkeit der Daten überzeugen, indem Sie den Blobspeicher überprüfen.
Zusammenfassung
In diesem Lernprogramm haben Sie die Data Factory-Benutzeroberfläche verwendet, um eine Pipeline zu erstellen, die Daten aus einer Data Lake Storage Gen2 Quelle in eine Data Lake Storage Gen2 Spüle kopiert und transformiert (beide den Zugriff auf nur ausgewählte Netzwerke ermöglicht), indem Sie den Zuordnungsdatenfluss in Data Factory Managed Virtual Network verwenden.