Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
Gilt für: Azure Logic Apps (Verbrauch + Standard)
Manchmal müssen Sie Inhalte in Token konvertieren, bei denen es sich um Wörter oder Zeichenblöcke handelt, oder ein großes Dokument in kleinere Teile aufteilen, bevor Sie diesen Inhalt mit bestimmten Aktionen verwenden können. Beispielsweise erwarten die aktionen Azure KI-Suche oder Azure OpenAI tokenisierte Eingaben und können nur eine begrenzte Anzahl von Token verarbeiten.
Verwenden Sie für diese Szenarien die Datenvorgänge-Aktionen Dokument parsen und Text segmentieren in Ihrem Logik-App-Workflow. Diese Aktionen transformieren Inhalte, z. B. ein PDF-Dokument, eine CSV-Datei, Excel Datei usw., in tokenisierte Zeichenfolgenausgabe und teilen die Zeichenfolge dann basierend auf der Anzahl der Token in Teile auf. Anschließend können Sie auf diese Ausgaben verweisen und sie mit nachfolgenden Aktionen in Ihrem Workflow verwenden.
Tipp
Um mehr zu erfahren, können Sie Azure Copilot diese Fragen stellen:
- Was versteht man in der künstlichen Intelligenz (KI) unter einem Token?
- Was ist eine tokenisierte Eingabe?
- Was ist eine tokenisierte Zeichenfolgenausgabe?
- Was bedeutet „Parsen“ in der künstlichen Intelligenz (KI)?
- Was bedeutet „Segmentieren“ (Blockerstellung) in der künstlichen Intelligenz (KI)?
Um Azure Copilot zu finden, wählen Sie auf der Symbolleiste des Azure-PortalsCopilot aus.
In diesem Handbuch wird gezeigt, wie Sie Aktionen zum Analysieren von Dokumenten und zum Abschnittstext in Ihrem Workflow hinzufügen und einrichten.
Einschränkungen und bekannte Probleme
In Verbrauchsworkflows ist die Aktion Parse a document nur in den folgenden Azure-Regionen verfügbar:
- Australien (Osten)
- Brasilien Süd
- Ostasien
- East US
- Ost-USA 2
- Nordeuropa
- Süd-Mittel-USA
- Südostasien
- Schweden, Mitte
- Westliches USA 2
- Westliches USA 3
- UK South
Diese Regionen bieten Datenquellenverbindungen, Dokumentverfolgung, Dokumentabschnitte, Unterstützung für Azure OpenAI-Einbettungsmodelle und integrierte Indizierungsunterstützung für das Abrufen von Daten. Weitere Informationen finden Sie unter Automate indexing in AI Search with workflows in Azure Logic Apps.
Die Aktionen Dokument parsen und Text segmentieren unterstützen derzeit keine Hostdateien, z. B. Mainframe- und Midrange-Binärdateien wie Virtual Storage Access Method (VSAM)-Dateien. Wenn Sie jedoch mit Standardworkflows arbeiten, können Sie stattdessen die integrierte Aktion IBM Host File mit dem Namen Hostdatei-Inhalte parsen verwenden.
Voraussetzungen
Ein Azure Konto und Abonnement. Wenn Sie nicht über ein Azure-Abonnement verfügen, Sign up for a free Azure account.
Ein Logik-App-Verbrauchs- oder -Standardworkflow mit einem vorhandenen Trigger, da die Vorgänge Dokument parsen und Text segmentieren nur als Aktionen verfügbar sind. Stellen Sie sicher, dass die Aktion zum Abrufen des Inhalts, den Sie parsen oder segmentieren (in Blöcke unterteilen) möchten, diesen Datenvorgängen vorangeht.
Dokument parsen
Die aktion Parse a document konvertiert Inhalt, z. B. ein PDF-Dokument, eine CSV-Datei, Excel Datei usw., in eine tokenisierte Zeichenfolge. Angenommen, Ihr Workflow beginnt mit dem Anforderungstrigger namens "Wenn eine HTTP-Anforderung empfangen wird". Dieser Trigger wartet auf den Empfang einer von einer anderen Komponente gesendeten HTTP-Anforderung, z. B. eine Azure-Funktion, einen anderen Logik-App-Workflow usw. Die HTTP-Anforderung enthält die URL für ein neues hochgeladenes Dokument, das für den Workflow zum Abrufen und Parsen verfügbar ist. Auf den Trigger folgt sofort eine HTTP-Aktion, die eine HTTP-Anforderung an die URL des Dokuments sendet und den Dokumentinhalt vom Speicherort zurückgibt.
Wenn Sie andere Inhaltsquellen wie Azure Blob Storage, SharePoint, OneDrive, Dateisystem, FTP usw. verwenden, können Sie überprüfen, ob Trigger für diese Quellen verfügbar sind. Sie können auch überprüfen, ob Aktionen zum Abrufen des Inhalts für diese Quellen verfügbar sind. Weitere Informationen finden Sie unter Integrierte Vorgänge und Verwaltete Connectors.
Öffnen Sie im Azure-Portal ihre Logik-App-Ressource und den Workflow im Designer.
Führen Sie unter dem vorhandenen Auslöser und den vorhandenen Aktionen folgende allgemeine Schritte zum Hinzufügen der Aktion Datenvorgänge namens Dokument parsen zu Ihrem Workflow aus.
Wählen Sie im Designer die Aktion Dokument parsen aus.
Daraufhin wird der Bereich „Aktionsinformationen“ geöffnet. Geben Sie dort auf der Registerkarte Parameter in der Eigenschaft Dokumentinhalt den Inhalt an, den Sie parsen möchten, indem Sie die folgenden Schritte ausführen:
Klicken Sie in das Feld Dokumentinhalt.
Die Optionen für die dynamische Inhaltsliste (Blitzsymbol) und den Ausdrucks-Editor (Funktionssymbol) werden angezeigt.
Um die Ausgabe einer vorherigen Aktion auszuwählen, verwenden Sie die dynamische Inhaltsliste.
Um einen Ausdruck zu erstellen, der die Ausgabe einer vorherigen Aktion bearbeitet, verwenden Sie den Ausdrucks-Editor.
In diesem Beispiel wird das Blitzsymbol für die dynamische Inhaltsliste ausgewählt.
Nachdem die dynamische Inhaltsliste geöffnet wurde, wählen Sie die gewünschte Ausgabe eines vorherigen Vorgangs aus.
In diesem Beispiel verweist die Aktion Dokument parsen auf die Ausgabe Text der HTTP-Aktion.
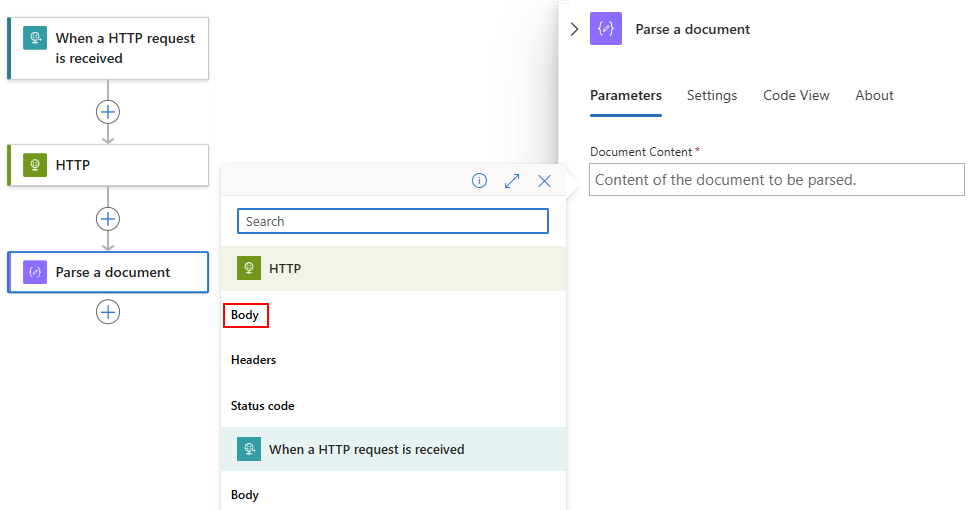
Die Ausgabe Text wird nun im Feld Dokumentinhalt angezeigt:
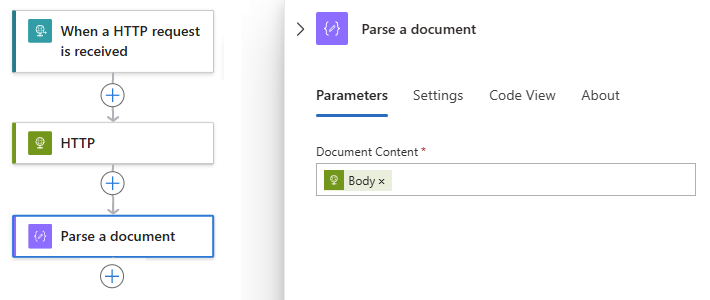
Fügen Sie unter der Aktion Dokument parsen die gewünschten Aktionen für die tokenisierte Zeichenfolgenausgabe hinzu, z. B. Text segmentieren (dies wird an späterer Stelle in diesem Leitfaden beschrieben).
Dokument parsen: Referenz
Parameter
| Name | Wert | Datentyp | BESCHREIBUNG | Begrenzung |
|---|---|---|---|---|
| Dokumentinhalt | < content-to-parse> | Any | Der zu analysierende Inhalt. | Keine |
Ausgaben
| Name | Datentyp | BESCHREIBUNG |
|---|---|---|
| Geparster Ergebnistext | Zeichenfolgenarray | Ein Array der Zeichenfolgen. |
| Geparstes Ergebnis | Object | Ein Objekt, das den gesamten geparsten Text enthält |
Text segmentieren
Die Aktion Text segmentieren teilt Inhalte in kleinere Teile auf (Blockerstellung), damit sie von nachfolgenden Aktionen im aktuellen Workflow einfacher verwendet werden können. Die folgenden Schritte basieren auf dem Beispiel aus dem Abschnitt Parse a Document und teilen die Ausgabe der Tokenzeichenfolge auf, um sie mit Azure AI-Operationen zu verwenden, die tokenisierte, kleine Inhaltsblöcke erwarten.
Hinweis
Vorherige Aktionen, die eine Segmentierung verwenden, haben keinen Einfluss auf die Aktion Text segmentieren, und die Aktion Text segmentieren wirkt sich nicht auf nachfolgende Aktionen mit Segmentierung aus.
Öffnen Sie im Azure-Portal ihre Logik-App-Ressource und den Workflow im Designer.
Führen Sie unter der Aktion Dokument parsen folgende allgemeine Schritte zum Hinzufügen der Aktion Datenvorgänge namens Text segmentieren aus.
Wählen Sie im Designer die Aktion Text segmentieren aus.
Daraufhin wird der Bereich „Aktionsinformationen“ geöffnet. Wählen Sie dort auf der Registerkarte Parameter für die Eigenschaft Segmentierungsstrategie die Option TokenSize als Segmentierungsmethode aus, sofern sie noch nicht ausgewählt ist.
Strategie BESCHREIBUNG TokenSize Teilt den angegebenen Inhalt basierend auf der Tokenanzahl auf Nachdem Sie die Strategie ausgewählt haben, klicken Sie in das Feld Text, um den Inhalt für die Segmentierung anzugeben.
Die Optionen für die dynamische Inhaltsliste (Blitzsymbol) und den Ausdrucks-Editor (Funktionssymbol) werden angezeigt.
Um die Ausgabe einer vorherigen Aktion auszuwählen, verwenden Sie die dynamische Inhaltsliste.
Um einen Ausdruck zu erstellen, der die Ausgabe einer vorherigen Aktion bearbeitet, verwenden Sie den Ausdrucks-Editor.
In diesem Beispiel wird das Blitzsymbol für die dynamische Inhaltsliste ausgewählt.
Nachdem die dynamische Inhaltsliste geöffnet wurde, wählen Sie die gewünschte Ausgabe eines vorherigen Vorgangs aus.
In diesem Beispiel verweist die Aktion Text segmentieren auf die Ausgabe Geparster Ergebnistext der Aktion Dokument parsen.

Das Textfeld zeigt jetzt die Ausgabe der Aktion Geparstes Ergebnis an:
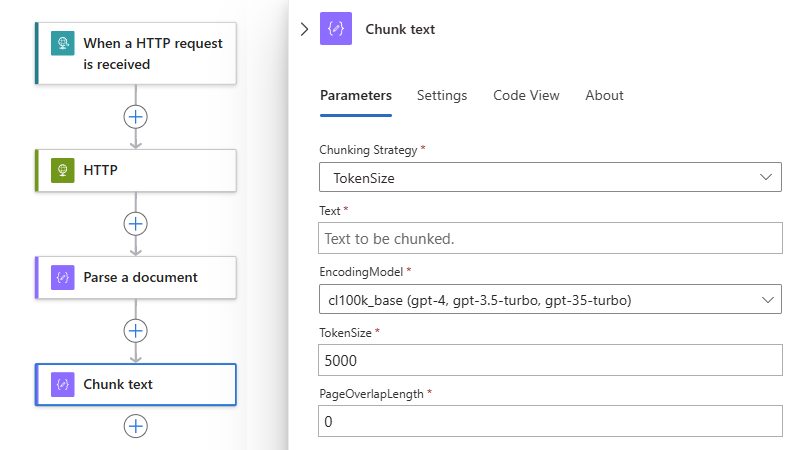
Führen Sie die Einrichtung für die Aktion Text segmentieren basierend auf Ihrer ausgewählten Strategie und Ihrem Szenario aus. Weitere Informationen finden Sie unter Text segmentieren: Referenz.
Wenn Sie nun andere Aktionen hinzufügen, die tokenisierte Eingaben erwarten und verwenden, z. B. die Azure KI-Aktionen, wird der Eingabeinhalt für eine einfachere Nutzung formatiert.
Text segmentieren: Referenz
Parameter
| Name | Wert | Datentyp | BESCHREIBUNG | Einschränkungen |
|---|---|---|---|---|
| Segmentierungsstrategie | TokenSize | Zeichenfolgenenumeration | Teilen Sie den Inhalt basierend auf der Tokenanzahl auf. Standard: TokenSize |
Nicht verfügbar |
| Text | < content-to-chunk> | Any | Der Inhalt, der segmentiert werden soll | Siehe Referenzleitfaden zu Grenzwerten und zur Konfiguration |
| EncodingModel | < Codierungsmethode> | Zeichenfolgenenumeration | Das zu verwendende Codierungsmodell: - Standardwert: cl100k_base (gpt4, gpt-3.5-turbo, gpt-35-turbo) - r50k_base (gpt-3) - p50k_base (gpt-3) - p50k_edit (gpt-3) - cl200k_base (gpt-4o) Weitere Informationen finden Sie in der Modellübersicht für OpenAI. |
Nicht verfügbar |
| TokenSize | < max-tokens-per-chunk> | Integer | Die maximale Anzahl von Token pro Inhaltsblock Standardwert: Keiner |
Mindestwert: 1 Höchstwert: 8.000 |
| PageOverlapLength | < Anzahl überlappender Zeichen> | Integer | Die Anzahl von Zeichen vom Ende des vorherigen Blocks, die im nächsten Block enthalten sein sollen. Mit dieser Einstellung können Sie verhindern, dass beim Aufteilen von Inhalten in Blöcke wichtige Informationen verloren gehen, und die Kontinuität sowie den Kontext über Blöcke hinweg beibehalten. Standardwert: 0 – es sind keine überlappenden Zeichen vorhanden. |
Mindestwert: 0 |
Tipp
Um mehr zu erfahren, können Sie Azure Copilot diese Fragen stellen:
- Was ist PageOverlapLength bei der Segmentierung?
- Was ist Codierung in Azure AI?
Um Azure Copilot zu finden, wählen Sie in der Azure-Portal-Symbolleiste Copilot aus.
Ausgaben
| Name | Datentyp | BESCHREIBUNG |
|---|---|---|
| Textelemente des segmentierten Ergebnisses | Zeichenfolgenarray | Ein Array der Zeichenfolgen. |
| Element in „Textelemente des segmentierten Ergebnisses“ | String | Eine einzelne Zeichenfolge im Array |
| Segmentiertes Ergebnis | Object | Ein Objekt, das den gesamten segmentierten Text enthält |
Beispielworkflow
Das folgende Beispiel enthält weitere Aktionen, die ein vollständiges Workflowmuster zum Erfassen von Daten aus einer beliebigen Quelle erstellen:
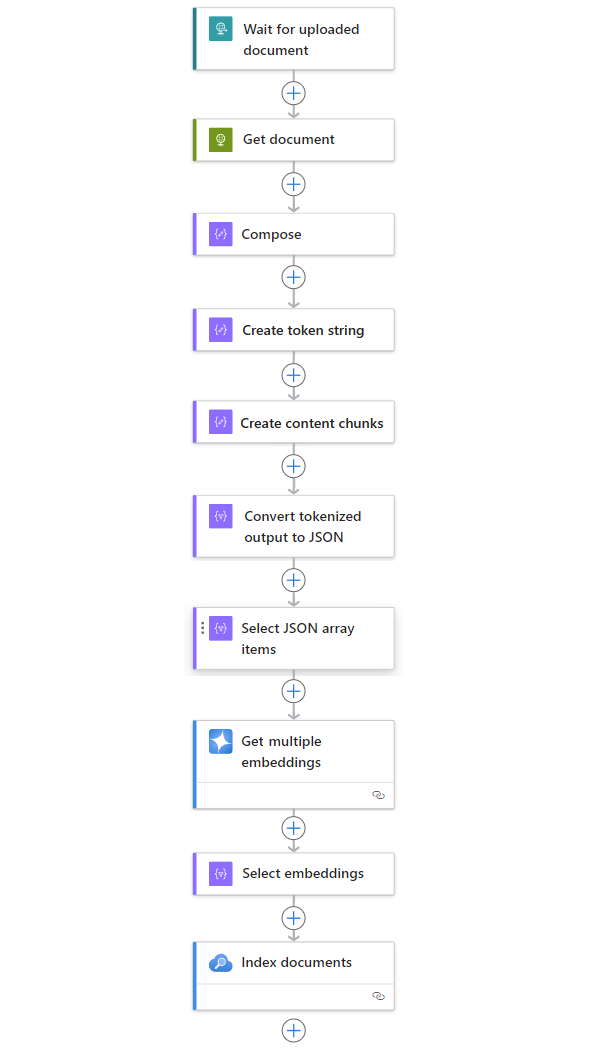
| Schritt | Aufgabe | Zugrunde liegender Vorgang | BESCHREIBUNG |
|---|---|---|---|
| 1 | Warten oder überprüfen, ob neue Inhalte vorhanden sind | Bei Eingang einer HTTP-Anforderung | Ein Trigger, der entweder eine Abfrage durchführt oder wartet, bis neue Daten eintreffen – entweder basierend auf einer geplanten Serie oder als Reaktion auf bestimmte Ereignisse. Ein solches Ereignis kann eine neue Datei sein, die in ein bestimmtes Speichersystem hochgeladen wird, z. B. Azure Blob Storage, SharePoint, OneDrive, Dateisystem, FTP usw. In diesem Beispiel wartet der Triggervorgang vom Typ Anforderung auf eine HTTP- oder HTTPS-Anforderung, die von einem anderen Endpunkt gesendet wurde. Die Anforderung enthält die URL für ein neues hochgeladenes Dokument. |
| 2 | Inhalt abrufen | HTTP | Eine HTTP-Aktion, die das hochgeladene Dokument unter Verwendung der Datei-URL aus der Triggerausgabe abruft. |
| 3 | Erstellen von Dokumentdetails. | Verfassen | Eine Datenvorgänge-Aktion, die verschiedene Elemente verkettet. In diesem Beispiel werden Schlüssel-Wert-Informationen zu dem Dokument verkettet. |
| 4 | Erstellen Sie eine Tokenzeichenfolge. | Dokument parsen | Eine Aktion unter Datenvorgänge, die anhand der Ausgabe der Aktion Erstellen eine tokenisierte Zeichenfolge erzeugt. |
| 5 | Erstellen Sie Inhaltsblöcke. | Text segmentieren | Eine Aktion unter Datenvorgänge, die die Tokenzeichenfolge basierend auf der Anzahl von Token pro Inhaltsblock aufteilt. |
| 6 | Tokenisierten und segmentierten Text in JSON konvertieren | Analysieren von JSON | Eine Aktion unter Datenvorgänge, die die segmentierte Ausgabe in ein JSON-Array konvertiert. |
| 7 | Auswählen von JSON-Arrayelementen | Auswählen | Eine Datenvorgänge-Aktion, die mehrere Elemente aus dem JSON-Array auswählt. |
| 8 | Generieren der Einbettungen | Abrufen mehrerer Einbettungen | Eine Azure OpenAIAktion, die Einbettungen für jedes JSON-Arrayelement erstellt. |
| 9 | Auswählen von Einbettungen und anderen Informationen | Auswählen | Eine Datenvorgänge-Aktion, die Einbettungen und andere Dokumentinformationen auswählt. |
| 10 | Indizieren der Daten. | Indizieren von Dokumenten | Eine Azure KI-SucheAktion, die die Daten basierend auf den ausgewählten Einbettungen indiziert. |