Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
Hinweis
In diesem Artikel wird die Integration von sparklyr mit Databricks Connect für Databricks Runtime 13.0 und höher beschrieben. Diese Integration wird weder von Databricks bereitgestellt noch direkt von Databricks unterstützt.
Falls Sie Fragen haben, wenden Sie sich an die Posit-Community.
Um Probleme zu melden, wechseln Sie zum Abschnitt Issues des Repositorys sparklyr im GitHub.
Weitere Informationen finden Sie unter Databricks Connect v2 in der sparklyr Dokumentation.
Mit Databricks Connect können Sie beliebte Entwicklungsumgebungen wie RStudio Desktop, Notizbuchserver und andere benutzerdefinierte Anwendungen mit Azure Databricks-Clustern verbinden. Weitere Informationen finden Sie unter Databricks Connect.
Hinweis
Databricks Connect verfügt über eingeschränkte Kompatibilität mit Apache Spark MLlib, da Spark MLlib RDDs verwendet, während Databricks Connect nur die DataFrame-API unterstützt. Um alle Sparklyr-MLlib-Funktionen zu verwenden, verwenden Sie Databricks-Notizbücher oder die db_repl Funktion des Brickster-Pakets.
In diesem Artikel wird veranschaulicht, wie Sie schnell mithilfe von Databricks Connect für R, sparklyr, und RStudio Desktop beginnen können.
- Informationen zu Databricks Connect für Python finden Sie unter Databricks Connect für Python.
- Informationen zu Databricks Connect für Scala finden Sie unter Databricks Connect für Scala.
Anleitung
Im folgenden Lernprogramm erstellen Sie ein Projekt in RStudio, installieren und konfigurieren Databricks Connect für Databricks Runtime 13.3 LTS und höher und führen einfachen Code für die Berechnung in Ihrem Databricks-Arbeitsbereich aus RStudio aus. Weitere Informationen zu diesem Tutorial finden Sie im Abschnitt „Databricks Connect“ unter Spark Connect und Databricks Connect v2 auf der sparklyr-Website.
In diesem Lernprogramm wird RStudio Desktop und Python 3.10 verwendet. Wenn sie noch nicht installiert sind, installieren Sie R und RStudio Desktop und Python 3.10.
Anforderungen
Um dieses Tutorial abzuschließen, müssen Sie die folgenden Anforderungen erfüllen:
- Ihr Ziel-Azure-Databricks-Arbeitsbereich und -Cluster müssen die Anforderungen für Compute-Konfiguration für Databricks Connect erfüllen.
- Sie müssen ihre Cluster-ID verfügbar haben. Um Ihre Cluster-ID abzurufen, klicken Sie in Ihrem Arbeitsbereich auf der Randleiste auf "Berechnen ", und klicken Sie dann auf den Namen Ihres Clusters. Kopieren Sie in der Adressleiste Ihres Webbrowsers die Zeichenfolge zwischen
clustersundconfigurationin der URL.
Schritt 1: Erstellen eines persönlichen Zugriffstokens
Hinweis
Databricks Connect für R-Authentifizierung unterstützt derzeit nur Azure Databricks persönliche Zugriffstoken.
In diesem Lernprogramm wird zur Authentifizierung mit Ihrem Azure Databricks-Arbeitsbereich eine persönliche Zugriffstoken-Authentifizierung verwendet.
Wenn Sie bereits über ein Azure Databricks persönliches Zugriffstoken verfügen, fahren Sie mit Schritt 2 fort. Wenn Sie nicht sicher sind, ob Sie bereits über ein Azure Databricks persönliches Zugriffstoken verfügen, können Sie diesen Schritt ohne Auswirkungen auf andere Azure Databricks persönliche Zugriffstoken in Ihrem Benutzerkonto ausführen.
Führen Sie zum Erstellen eines persönlichen Zugriffstokens die Schritte unter Erstellen von persönlichen Zugriffstoken für Arbeitsbereichsbenutzer aus.
Schritt 2: Erstellen des Projekts
- Starten Sie RStudio Desktop.
- Klicken Sie im Hauptmenü auf File > New Project.
- Wählen Sie Neues Verzeichnis aus.
- Wählen Sie Neues Projekt aus.
- Geben Sie den Namen des neuen Projektverzeichnisses für Verzeichnisname und den Ort, an dem das neue Projektverzeichnis erstellt werden soll, für Projekt erstellen als Unterverzeichnis des ein.
- Wählen Sie Für dieses Projekt renv verwenden aus. Wenn Sie aufgefordert werden, eine aktualisierte Version des Pakets
renvzu installieren, wählen Sie Ja aus. - Klicken Sie auf Create Project.

Schritt 3: Hinzufügen des Databricks Connect-Pakets und anderer Abhängigkeiten
Wählen Sie im Hauptmenü von RStudio Desktop Extras > Pakete installieren aus.
Behalten Sie für Installieren von die Einstellung Repository (CRAN) bei.
Geben Sie unter Pakete die folgende Paketliste ein. Dabei handelt es sich um die Voraussetzungen für das Databricks Connect-Paket und dieses Tutorial:
sparklyr,pysparklyr,reticulate,usethis,dplyr,dbplyrBehalten Sie für In Bibliothek installieren Ihre virtuelle R-Umgebung bei.
Stellen Sie sicher, dass Abhängigkeiten installieren aktiviert ist.
Klicken Sie auf Installieren.

Wenn Sie in der Konsolenansicht (Ansicht > Fokus auf Konsole verschieben) aufgefordert werden, mit der Installation fortzufahren, geben Sie
Yein. Die Paketesparklyrundpysparklyrund ihre Abhängigkeiten werden in Ihrer virtuellen R-Umgebung installiert.Verwenden Sie im Bereich Console
reticulate, um den folgenden Befehl auszuführen, um Python zu installieren. (Databricks Connect für R erfordert, dass zuerstreticulateund Python installiert werden.) Ersetzen Sie im folgenden Befehl3.10durch die Haupt- und Nebenversion der Python Version, die auf Ihrem Azure Databricks Cluster installiert ist. Informationen zu dieser Haupt- und Nebenversion finden Sie im Abschnitt "Systemumgebung" der Versionshinweise für die Databricks-Runtime-Version Ihres Clusters in den Versionshinweisen und Kompatibilitätshinweisen zur Databricks-Runtime.reticulate::install_python(version = "3.10")Installieren Sie im Konsolenbereich das Databricks Connect-Paket, indem Sie den folgenden Befehl ausführen. Ersetzen Sie im folgenden Befehl
13.3durch die Databricks-Runtime-Version, die auf Ihrem Azure Databricks Cluster installiert ist. Um diese Version zu finden, navigieren Sie in Ihrem Azure Databricks-Arbeitsbereich auf die Detailseite Ihres Clusters und sehen Sie im Konfigurationsreiter den Abschnitt Databricks Runtime Version ein.pysparklyr::install_databricks(version = "13.3")Wenn Sie die Databricks Runtime-Version für Ihren Cluster nicht kennen oder sie nicht nachschlagen möchten, können Sie stattdessen den folgenden Befehl ausführen.
pysparklyrfragt den Cluster ab, um die zu verwendende Databricks Runtime-Version zu ermitteln:pysparklyr::install_databricks(cluster_id = "<cluster-id>")Wenn Ihr Projekt später eine Verbindung mit einem anderen Cluster herstellen soll, der dieselbe Databricks-Runtime-Version aufweist wie die soeben angegebene, verwendet
pysparklyrdieselbe Python Umgebung. Wenn der neue Cluster über eine andere Databricks Runtime-Version verfügt, sollten Sie den Befehlpysparklyr::install_databrickserneut mit der neuen Databricks Runtime-Version oder Cluster-ID ausführen.
Schritt 4: Festlegen von Umgebungsvariablen für Arbeitsbereich-URL, Zugriffstoken und Cluster-ID
Databricks empfiehlt, keine sensiblen oder sich ändernden Werte wie Ihre Azure Databricks-Arbeitsbereichs-URL, persönlichen Zugriffstoken oder Cluster-ID in Ihre R-Skripte hart zu codieren. Speichern Sie diese Werte stattdessen separat, z. B. in lokalen Umgebungsvariablen. In diesem Lernprogramm wird die integrierte Unterstützung von RStudio Desktop zum Speichern von Umgebungsvariablen in einer .Renviron Datei verwendet.
Erstellen Sie eine
.Renviron-Datei zum Speichern der Umgebungsvariablen (sofern diese Datei noch nicht vorhanden ist), und öffnen Sie dann diese Datei zur Bearbeitung. Führen Sie an der RStudio Desktop-Konsole den folgenden Befehl aus:usethis::edit_r_environ()Geben Sie in der angezeigten
.Renviron-Datei (Ansicht > Fokus auf Quelle verschieben) den folgenden Inhalt ein. Ersetzen Sie in diesem Inhalt die folgenden Platzhalter:- Ersetzen Sie
<workspace-url>durch Ihre arbeitsbereichsspezifische URL, z. B.https://adb-1234567890123456.7.azuredatabricks.net. - Ersetzen Sie
<personal-access-token>durch Ihr Azure Databricks persönliches Zugriffstoken aus Schritt 1. - Ersetzen Sie
<cluster-id>mit der Cluster-ID aus den Anforderungen dieses Lernprogramms.
DATABRICKS_HOST=<workspace-url> DATABRICKS_TOKEN=<personal-access-token> DATABRICKS_CLUSTER_ID=<cluster-id>- Ersetzen Sie
Speichern Sie die Datei
.Renviron.Laden Sie die Umgebungsvariablen in R, indem Sie im Hauptmenü Sitzung > R neu starten auswählen.

Schritt 5: Hinzufügen von Code
Wählen Sie im Hauptmenü von RStudio Desktop Datei > Neue Datei > R-Skript aus.
Geben Sie den folgenden Code in die Datei ein, und speichern Sie sie (Datei > Speichern) unter
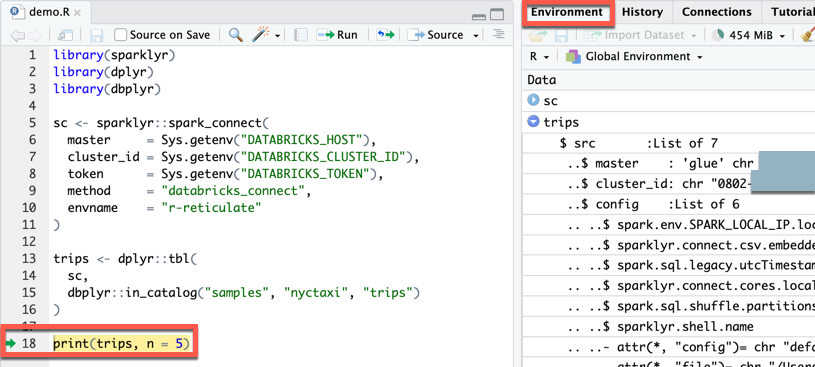
demo.R:library(sparklyr) library(dplyr) library(dbplyr) sc <- sparklyr::spark_connect( master = Sys.getenv("DATABRICKS_HOST"), cluster_id = Sys.getenv("DATABRICKS_CLUSTER_ID"), token = Sys.getenv("DATABRICKS_TOKEN"), method = "databricks_connect", envname = "r-reticulate" ) trips <- dplyr::tbl( sc, dbplyr::in_catalog("samples", "nyctaxi", "trips") ) print(trips, n = 5)
Schritt 6: Ausführen des Codes
Wählen Sie in RStudio Desktop auf der Symbolleiste für die Datei
demo.Rdie Option Quelle aus.
In der Konsole werden die ersten fünf Zeilen der Tabelle
tripsangezeigt.In der Ansicht Verbindungen (Ansicht > Verbindungen anzeigen) können Sie die verfügbaren Kataloge, Schemas, Tabellen und Sichten erkunden.

Schritt 7: Debuggen des Codes
- Wählen Sie in der Datei
demo.Rden Bundsteg nebenprint(trips, n = 5)aus, um einen Breakpoint festzulegen. - Wählen Sie auf der Symbolleiste für die Datei
demo.Rdie Option Quelle aus. - Wenn der Code am Breakpoint angehalten wird, können Sie die Variable in der Ansicht Umgebung (Ansicht > Umgebung anzeigen) überprüfen.
- Wählen Sie im Hauptmenü Debuggen > Fortsetzen aus.
- In der Konsole werden die ersten fünf Zeilen der Tabelle
tripsangezeigt.